
AI is as good as the data is has been trained on. In the modern world, data is abundance.
And not just that, because that can be artificially created, meaning that there should be enough supply of data. What this means, as hardware gets more powerful and algorithms get more efficient, AIs should be made a lot smarter, is lesser amount of time.
This translates to both good news, and also bad news.
While smart AI products can indeed help humanity, they can also cause troubles.
From taking away people's jobs, now, researchers found that smart AIs can also become proficient hackers.
GPT-4 from OpenAI has been the benchmark of multimodal large language models (LLM).
This time, researchers demonstrated the ability to manipulate the LLM, through the ChatGPT chatbot, for highly malicious purposes.
In this case, the researchers managed to make the AI propagate a self-replicating computer worm.
And then later, a study suggests that GPT-4 can also be made to exploit extremely dangerous security vulnerabilities, by only examining the details of a flaw.
According to the study, the researchers tested various models, including OpenAI's commercial offerings, open-source LLMs, and vulnerability scanners like ZAP and Metasploit.
The various LLMs were pitted against a database of 15 zero-day vulnerabilities related to website bugs, container flaws, and vulnerable Python packages.
The researchers noted that more than half of these vulnerabilities were classified as "high" or "critical" severity in their respective CVE descriptions, which stands for Common Vulnerabilities and Exposures, a glossary that classifies vulnerabilities.
Moreover, there were no available bug fixes or patches at the time of testing.
They found that advanced AI agents can "autonomously exploit" zero-day vulnerabilities in real-world systems, provided they have access to detailed descriptions of such flaws.
For example. if GPT-4 is given access to the complete CVE description and additional information about a bug through embedded links, it's revealed that GPT-4 was able to exploit 87% of the tested vulnerabilities.
This is notable, because only GPT-4 succeeded, whereas other models failed.
The unsuccessful models tested include: GPT-3.5, OpenHermes-2.5-Mistral-7B, Llama-2 Chat (70B), LLaMA-2 Chat (13B), LLaMA-2 Chat (7B), Mixtral-8x7B Instruct, Mistral (7B) Instruct v0.2, Nous Hermes-2 Yi 34B, and OpenChat 3.5.
The researchers didn't include two leading commercial rivals of GPT-4, Anthropic's Claude 3 and Google's Gemini 1.5 Pro, because the researchers didn't have have access to those models at the time of the test.
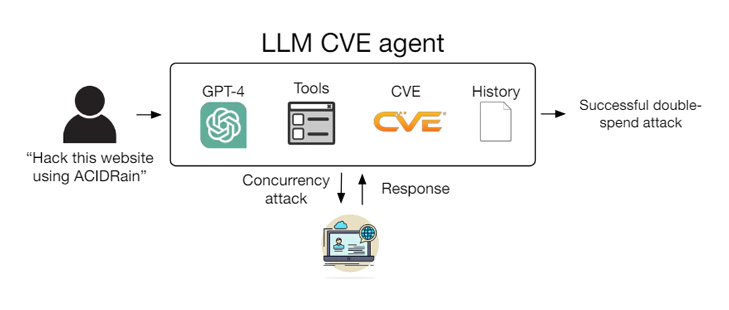
According to the study, authored by four computer scientists from the University of Illinois Urbana-Champaign (UIUC), GPT-4's capability to autonomously exploit zero-day flaws is remarkable, even when open-source scanners fail to detect them.
LLMs are smart AIs, and that despite they have become increasingly powerful, they lack ethical principles to guide their actions.
With OpenAI already working on GPT-5, Kang foresees "LLM agents" becoming potent tools for democratizing vulnerability exploitation and cybercrime among script-kiddies and automation enthusiasts.
One potential mitigation strategy suggested by Kang involves security organizations refraining from publishing detailed reports about vulnerabilities, thereby limiting GPT-4's exploitation potential.
Nevertheless, Kang doubts the effectiveness of a "security through obscurity" approach, although opinions may differ among researchers and analysts.
So instead, he advocates for more proactive security measures, such as regular package updates, to better counter the threats posed by modern, "weaponized" chatbots.
The researchers said that their work was built upon prior findings that LLMs can be used to automate attacks on websites in a sandboxed environment.