

In the AI field, humans have ventured and learned so far, but to understand so much less.
Inside deep learning systems, there are neural networks that act as their core software. Although humans have managed to create various types of AIs, humans actually understand them very poorly.
We have managed to create these products without understanding why they work the way they do.
Researchers at MIT have taken a huge step to answer this question.
In a paper authored by Jonathan Frankle and Michael Carb, it's described that within every neural network exists a far smaller one that can be trained to achieve the same performance as its oversize parent. In some cases, according to the researchers, they can be 10 or even 100 times smaller.
What this means, we humans have long use neural networks far bigger than we actually need.
If researchers struggle to train AI due to the magnitude of time and computational power, this finding could be the answer to their problem. If we can find a way to tap into these smaller networks, we can potentially unlock the ability to create much more powerful AI using the much smaller hardware.
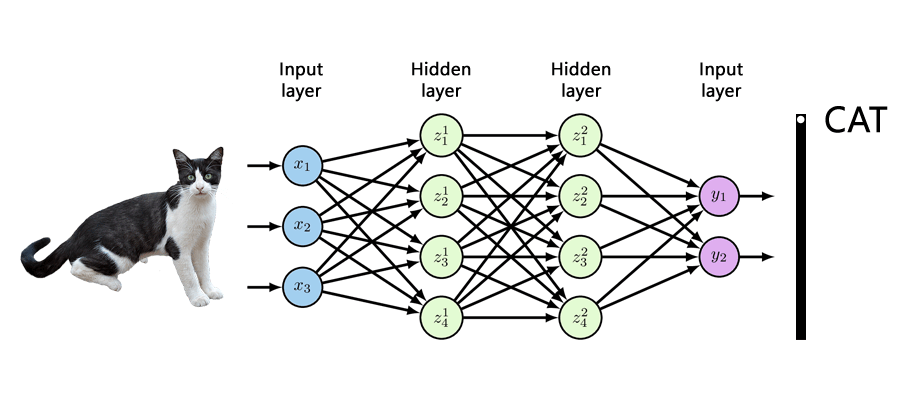
To understand why this is possible, one should first dive into how neural networks work.
In the above diagram, shows a stacked layers of computational nodes that are connected in order to compute patterns in data.
Before a neural network is trained, these connections are assigned random values between 0 and 1 to represent their intensity. This is called the "initialization" process. During training, as the network is fed with a series of data, let's say photos of animals.
Here, the network will tweak those intensities, in ways like how humans' brain would strengthen or weaken different neuron connections as they learn from experience and knowledge.
After training is done, the final connection intensities are then used in perpetuity recognize animals in new photos.
These are the mechanics of an AI's neural network, and researchers know this very well. But the reason why they work that way has remained a mystery.
This lack of knowledge led to why researchers can't really figure out why AIs came to certain conclusion, or also called a "black box".
Through studies and experiments, researchers have observed two properties of neural networks that have proved useful.
- When a network is initialized before the training process, there’s always some likelihood that the randomly assigned connection strengths end up in an untrainable configuration. Large networks have lesser changes of errors, and this is why researchers typically use very large networks for their deep learning tasks to increase their chances of achieving a successful model.
- The result of this practice is that, a neural network usually starts bigger than it needs to be. Once it’s done training, typically only a fraction of its connections remain strong, while the others end up pretty weak or even useless.
Researchers have long exploited the second observation, which is shrinking their networks after training to lower the time and computational costs needed in running them.
But no one thought it was possible to shrink their networks before training.
Researchers have long assumed that they had to start with an oversize network and the training process had to run its course in correct order to separate the relevant connections from the irrelevant ones.
Jonathan Frankle, the MIT PhD student who coauthored the paper, questioned that assumption. “If you need way fewer connections than what you started with, why can’t we just train the smaller network without the extra connections?”
And this turns out to be possible.
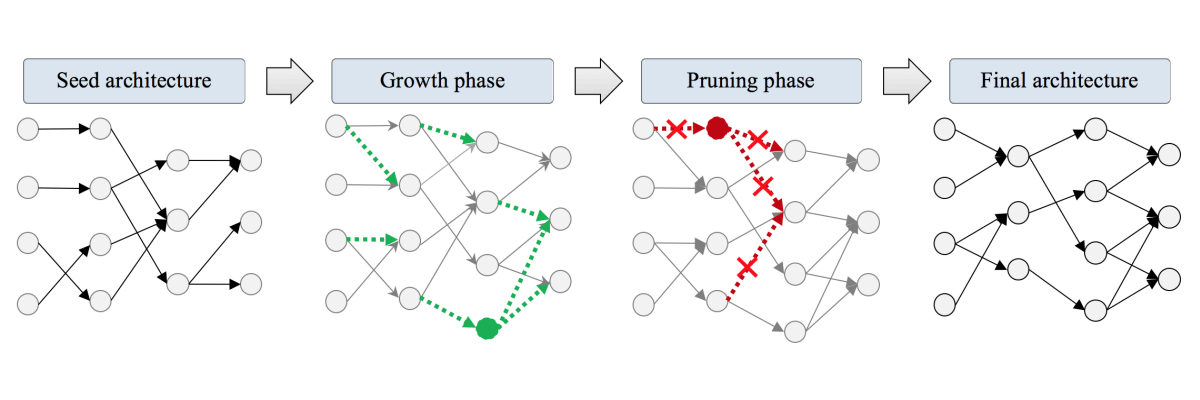
The researchers' discovery was based on the fact that random connection strengths assigned during initialization aren’t actually random in their consequences: they predispose different parts of the network to fail or succeed before training even happens.
In other words, the initial configuration influences which final configuration the network will arrive at.
Using this idea, the researchers found that if they remove nodes from an oversize network after training, they can still reuse the resultant smaller network to train on new data and preserve high performance, as long as they reset each connection within this downsized network back to its initial strength.
From this finding, Frankle and his coauthor Michael Carbin, an assistant professor at MIT, propose what they call the “lottery ticket hypothesis.”
This is when you randomly initialize a neural network’s connection strengths, it’s like buying a bag of lottery tickets. Within that bag, you hope that there is a winning ticket (an initial configuration that will be easy to train and result in a successful model).
This also explains why that observation number one is true.
Starting with a larger network is like buying more lottery tickets. Here, researchers aren't increasing the amount of power to their deep learning model, instead, they are simply increasing the chances that they will have a winning configuration.
Once that winning configuration is found, rather than continue to replay the lottery, researchers should be able to reuse it again and again, .
In the research, Frankle and Carbin initiated a brute-force approach of training and pruning an oversize network with one data set to extract the winning ticket for another data set. In theory, there should be much more efficient ways of finding or even designing a winning configuration from the start.
And as for the smallest size possible, Frankel found that he was able to consistently reduce the starting network to between 10 percent and 20 percent of its original size. But again, there should be ways to make it even smaller.