Most if not all Artificial Intelligence relied on humans feeding its systems some information to start.
From translation to photo tagging, autonomous machines, speech recognition, computers that play games better than humans and more others, they have systems that learned they way out. Their creators have first fed the AIs with dataset to make them understand the patterns so they can work as intended.
But according to OpenAI, that shouldn't always be the case.
As a start, the researchers at the non-profit organization co-founded by Elon Musk, found that without any human-provided information or guidance, AI can explore more than 50 video games, and even beat some of them.
This is because AI can also be "curious."
The curious algorithm would try to predict what its environment would look like one frame into the future. When that next frame happened, the algorithm would be rewarded by how wrong it was. The idea is that if the algorithm could predict what would happen in the environment, it had seen it before.
In a published research paper titled Large-Scale Study of Curiosity-Driven Learning, the researchers detailed a large-scale study on curiosity-driven learning. In it, they show how AI models trained without "extrinsic rewards" can also develop and learn new skills.
Basically, the researchers made this happened by not giving an AI any explicit goals. In short, the AI is left on its own to learn by itself, without understanding the rules.
The idea behind this project, is allowing machines to explore the environments without any human-coded rewards.
According to the team’s white paper:
To study the effects, the researchers put the AI into games, as the environments are suited to AI research because of their inherent rules and rewards. They tried the AI using Atari games, Super Mario Bros., virtual 3D navigation in
Unity, multi-player Pong, and Roboschool environments.
The team then investigated different random features, pixels, inversedynamics and variational auto-encoders to evaluate the dynamics-based curiosity's generalization to unseen environments.
The developers can tell the AI to play, for example, Pong, and give it only specific conditions like "don’t lose." This resulted to the AI in creating its own rules, which can eventually led to it prioritizing scoring points. And when it plays Breakout, it performs well because it doesn’t want to get bored, and is motivated to experience new things.
.
The AI also passed 11 levels of Super Mario Bros., just out of sheer curiosity.
But this curiosity also comes with a cost.
When researchers pitted two curious Pong-playing bots against one another, they gave up playing the match and decided to see how many volleys they could achieve together. And because the AI agent was rewarded for seeing new things when playing games, sometimes, the AI would kill itself on purpose just to see the Game Over screen.
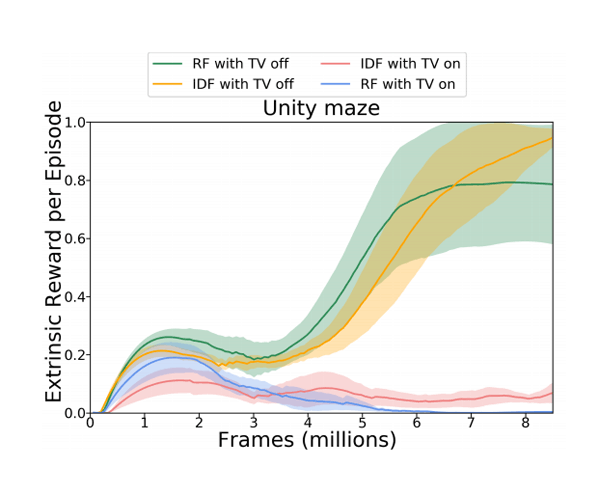
The research team tested this using a common thought-experiment called the “Noisy TV Problem.” And according to the team’s white paper:
The experiment showed that the AI agents can indeed get distracted. There was a significant dip in performance when the AI tried to run a maze and found a virtual TV. The static on a TV is immensely random, and this made the curious AI agent to never truly predict what would happen next.
With the researchers testing their theory by giving a digital TV inside a 3D environment, and allowing the agent to press a button to change the channel, the agent found the TV and started flipping through the channels, the stream of new images made the TV irresistible and the AI got drawn into watching the TV forever.
There were instances where the AI could pull itself away from the TV. But that only happened when the AI’s surroundings somehow seemed more interesting than the next thing on TV.
So here, curious AI can make learning more unsupervised. But just like humans, curious machines also suffer from the same kind of problems: they can be distracted.