
Google is the search engine giant, and that it deploys crawlers to scout and reach all corners of the web.
It does this to gather as much information as possible, and as quickly as it can. The only places it cannot venture, include content behind paywalls or anything behind a login page, and dark web, and the many web pages that have no backlinks or sitemap.
Google can also be stopped using restrictions put on websites' robots.txt file.
Other than those, Google has a free pass to enter and leave whenever it wants.
And since the rise of generative AIs, which was pioneered by OpenAI when it introduced ChatGPT, Google is doing something its rival cannot.
And that is tapping into the immensely capable search engine to help train Google Bard, and saying that it has the right to use any data it can find, as if it's always for it to take.
Google updated its privacy policy, to explicitly say that the company reserves the right to scrape just about everything people post online to build its AI tools
Read: Google Finally Unleashed 'Bard', Its ChatGPT-Competitor, For The Public To Test
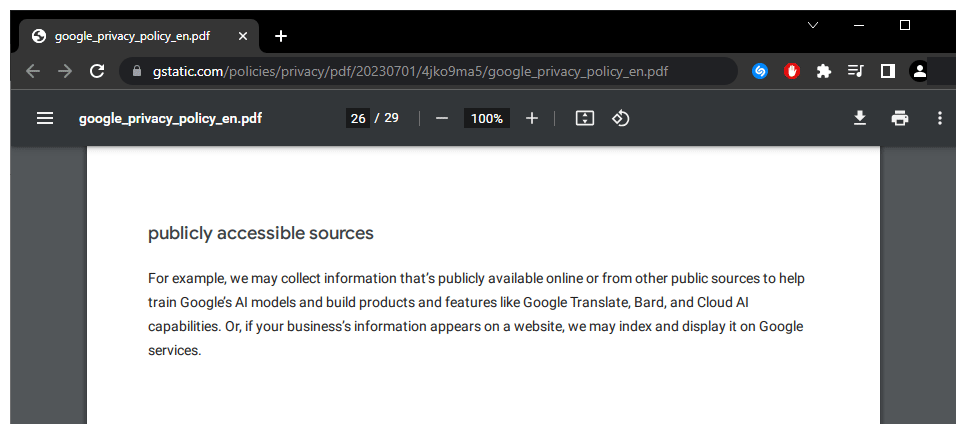
Under the "publicly accessible sources," the company said that:
In other words, if Google Search can find it, it's presumed that those words are for the taking.
Google's privacy policy is one of those pages that change very frequently.
Google maintains an archive to document the history of changes it made to its terms of service.
Previously, Google said the data would be used "for language models," rather than "AI models," and where the older policy just mentioned Google Translate, this time, Bard and Cloud AI also make an appearance.
What's worth noting here is that, the addition is kind of unusual for a clause at a privacy policy.
Traditionally, privacy policies only describe ways that a business may use the information that users post on the company's own services. But here, Google is making it clear that it has the right to harness data posted on any part of the public web, as if the whole internet is the company's own playground.

So of course, this privacy policy raises privacy questions.
On the web, netizens generally know that any post can become public, and that a post made public is a post for the world to see.
But in the revised privacy policy, Google is making a statement to say that whatever people write online, it's no longer a question of who can see the information, but how it could be used.
In an example, Google has the very right to train its AI on long-forgotten posts of netizens, that can be embarrassing to remember.
But what should be noted here is that, Bard is just like OpenAI's ChatGPT and Microsoft's Bing chatbot, and some others, in which they all have scraped portions of the internet to fuel their bot.
The privacy policy here is only a way to make it clear, that Google doesn't want people to argue about it, even if they must.