
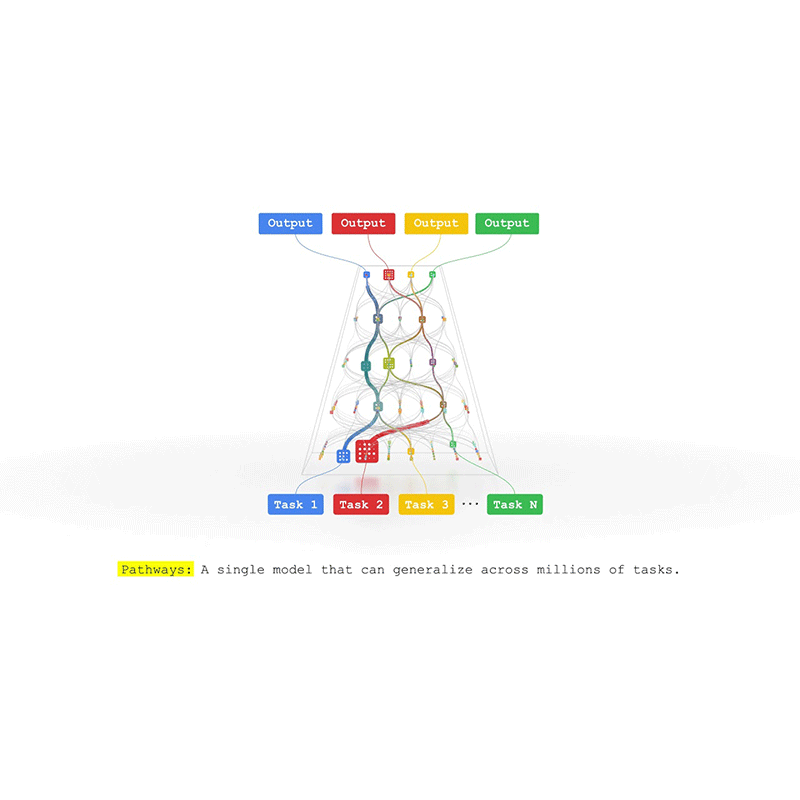
More than often, AI systems are overspecialized at individual tasks, when they could actually excel at many other tasks.
This is why Google created what it calls the 'Pathways'. This AI architecture is meant to that will handle many tasks at once, learn new tasks quickly and reflect a better understanding of the world. The single model introduced in 2021 was able to generalize across domains and tasks while being efficient.
Building on top of that effort, Google announced 'PaLM'.
Short for 'Pathways Language Model', the algorithm is considered a step toward AI architecture, which allows computers to handle millions of different tasks, including complex learning and reasoning.
PaLM overcomes the more traditional state of AI, beating humans in language and reasoning tests.
Google managed to do this by training PaLM with 540 billion parameters, a number that is larger than even the powerful OpenAI's GPT-3. In a blog post, Google explained that:
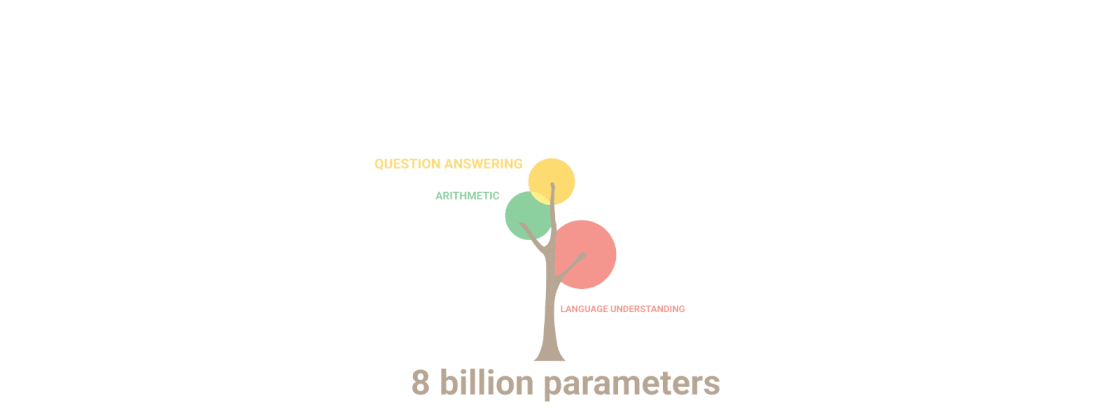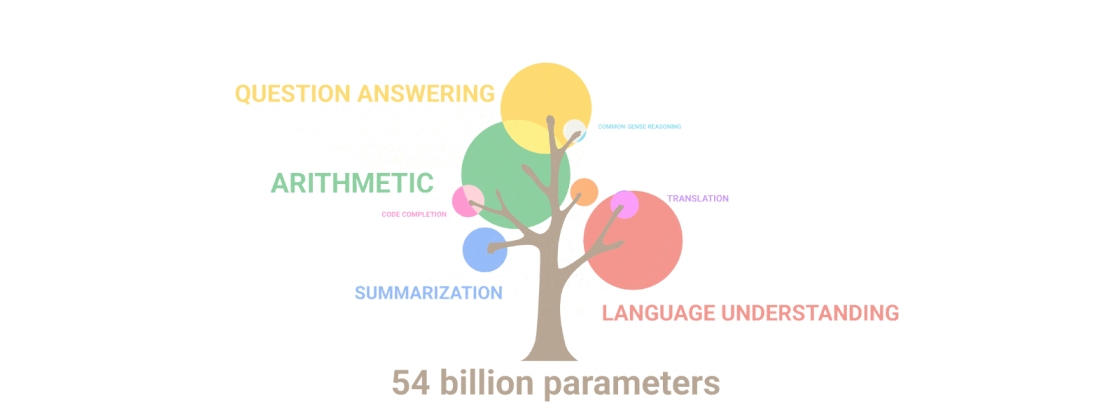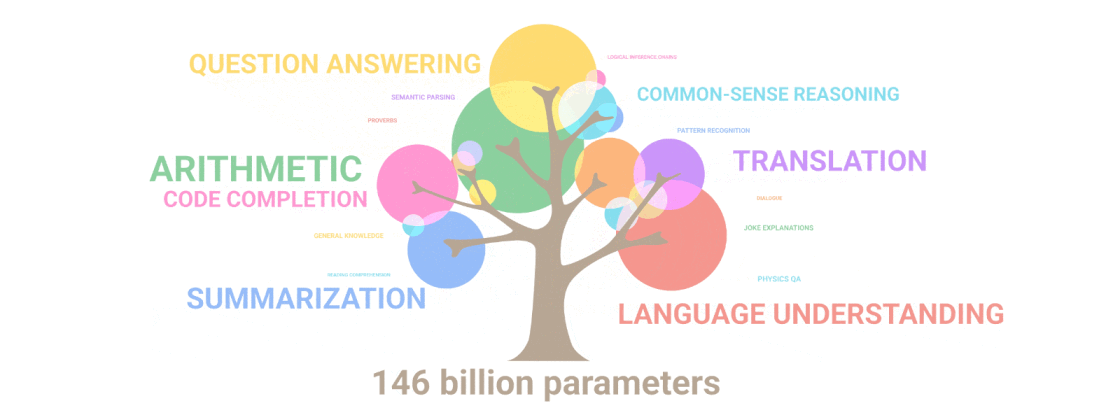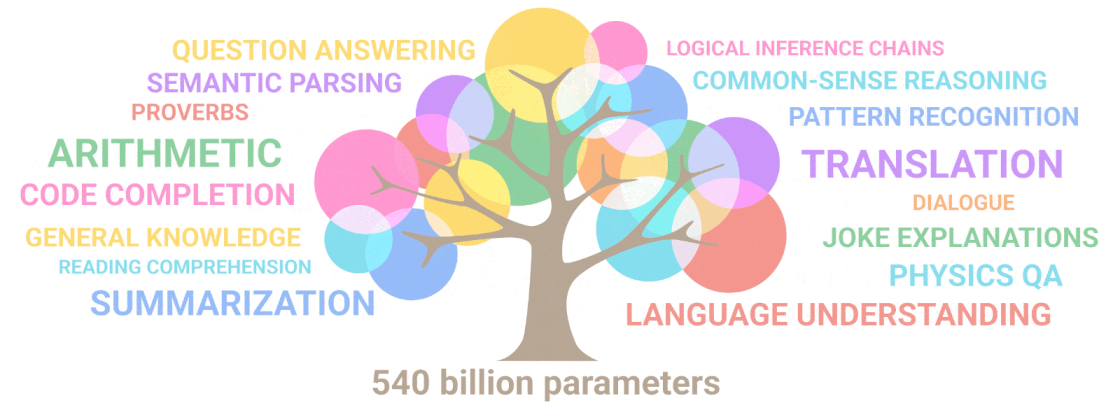
But the number is only one of the equations.
Google managed to accomplish the feat because PaLM's dense decoder-only Transformer model enabled researchers to efficiently train a single model across multiple TPU v4 Pods, using a method called 'few-shots'.
Few-shot learning is the next stage of learning that is moving beyond deep learning..
"We evaluated PaLM on hundreds of language understanding and generation tasks, and found that it achieves state-of-the-art few-shot performance across most tasks, by significant margins in many cases," the researchers explained.
According to Google Brain's researcher, Hugo Larochelle, the biggest problem with deep learning is that researchers have to collect a vast amount of data. Because each task requires millions of examples from which the AI can learn from, the process requires significantly extensive human labor.
Because of this, he pointed out that deep learning is likely not the path towards an AI that can solve many tasks.
Few-shot learning on the other hand, allows researchers to "attack" the problem by generalizing from little amounts of data.
Because the process of developing the "right algorithm" involves the researchers' intuition, Larochelle calls the process "meta learning."
The goal with the few-shot approach, is to approximate how humans learn different things, and then let the AI put the different bits of knowledge together in order to solve new problems that have never before been encountered.
The result is a machine that can use its knowledge it has to solve new problems.

In the case of PaLM, an example of this capability is its ability to explain a joke that it has never encountered before.
This is because PaLM can generate explicit explanations for scenarios that require a complex combination of multi-step logical inference, world knowledge, and deep language understanding.
PaLM can also distinguish cause and effect, understand conceptual combinations in appropriate contexts, and even guess a movie from just seeing an emoji.
The model can also label cause and effect, and finding synonyms and counterfactuals.
"By combining model scale with chain-of-thought prompting, PaLM shows breakthrough capabilities on reasoning tasks that require multi-step arithmetic or common-sense reasoning. Prior LLMs, like Gopher, saw less benefit from model scale in improving performance," Google said.