
While coding can be difficult, analyzing lines of programming language for efficiency and performance improvement can be equally daunting.
Traditionally, developers can use things like performance model of compilers through a simulation to run basic blocks — the sequence of boot-up, execute, and shut down — of code in order to gauge the performance of a chip. However, these performance models are not often validated through real-life performance.
This is why researchers from the Massachusetts Institute of Technology (MIT) developed a machine learning-based tool capable of telling how fast a code can run on various chips.
This should certainly help developers tweak their applications for various processor architectures.
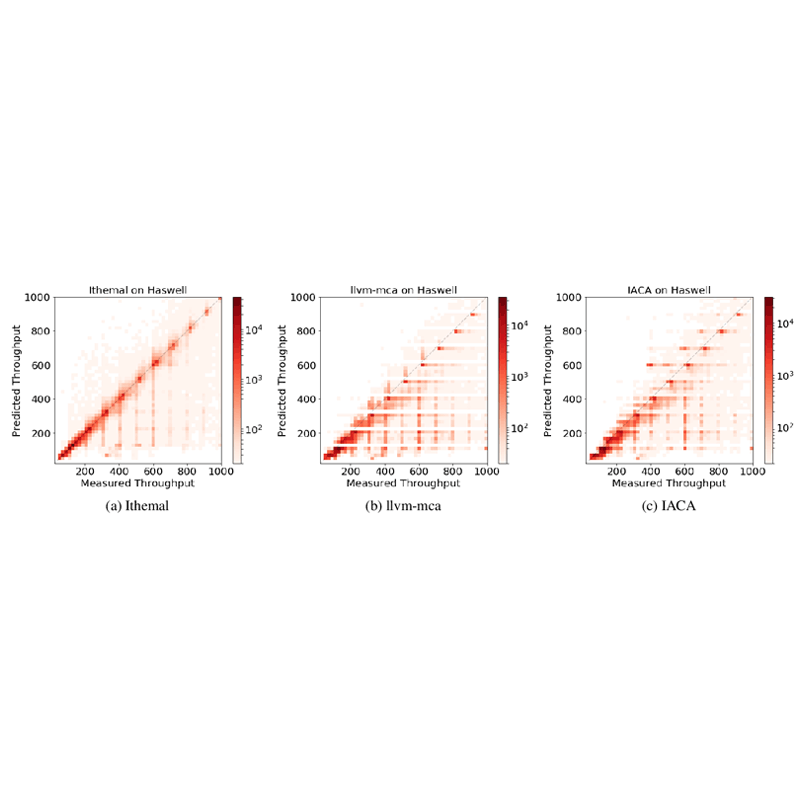
With the AI the MIT researchers call 'Ithmel', developers can quickly predict how fast a chip can run unknown basic blocks.
The researchers have also updated the AI to support a database called BHive, which include 300,000 basic blocks from specialized fields such as machine learning, cryptography, and graphics.
According to Michael Carbin, a co-author of the paper and an assistant professor in the Department of Electrical Engineering and Computer Science (EECS):
To make this AI work, the researchers clocked the average number of cycles a given microprocessor takes to compute basic block instructions without human intervention.
By automating the process, the researchers were able to rapidly profile hundreds of thousands or millions of blocks.
"Importantly, Ithemal takes raw text as input and does not require manually adding features to the input data. In testing, Ithemal can be fed previously unseen basic blocks and a given chip, and will generate a single number indicating how fast the chip will execute that code," the researchers said.
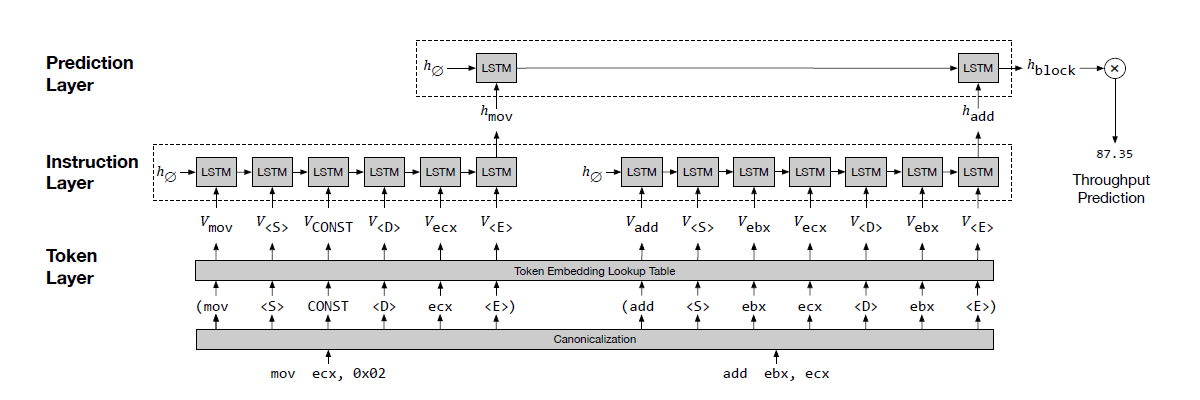
The tool makes it easier to quickly learn performance speeds for any new chip architectures, explained co-author Charith Mendis.
For instance, domain-specific architectures, such as Google’s Tensor Processing Unit used specifically for neural networks, are being built but aren’t widely understood.
“If you want to train a model on some new architecture, you just collect more data from that architecture, run it through our profiler, use that information to train Ithemal, and now you have a model that predicts performance,” Mendis said.
Next, the researchers are studying methods to make models interpretable. Much of machine learning is a black box, in which people don't really know why a particular model made its predictions.
“Our model is saying it takes a processor, say, 10 cycles to execute a basic block. Now, we’re trying to figure out why,” Carbin says. “That’s a fine level of granularity that would be amazing for these types of tools.”
"Ultimately," the researchers wrote, "developers and compilers can use the tool to generate code that runs faster and more efficiently on an ever-growing number of diverse and black box chip designs.
The team of researchers presented a paper at the NeuralIPS conference in December to describe a novel method to measure code performance on various processors. The paper also describes Vemal, an automatically-generating algorithm that can be used to generate compiler optimizations.
The researchers hope to use Ithemal to enhance the performance of Vemal even further and achieve better performance.