

AI holds a lot of promise. And this is why the field is heavily-developed by many researchers from different companies, universities and organizations.
The technology works with machine learning that has neural networks that mimic the behavior of neurons in a human brain.
This way, researchers have managed to make computers exceptionally well in predicting things, calculating huge amount of data, health diagnosing, face recognition and many many more.
Out of the many implementations of AIs in the real world, text-to-speech is one of which that holds a particular promise.
This is why Facebook wants to go a step further, with its researchers creating an AI ‘polyglot’ system that is able to, given voice data, produce new speech samples in multiple languages.
Here’s the AI translating Spanish to English:
And here is translating German to English:
The team describes their work in a paper titled "Unsupervised Polyglot Text-to-Speech" published on Arxiv.org:
“[It can] take a sample of a speaker talking in one language and have [them] … speak as a native speaker in another language."
The TTS AI consists of a number of components shared among languages, and two types of language-specific components:
- A per-language encoder that embedded input sequences of perceptually distinct units of sound in an algebraic model called a “vector space.”
- A network that, given a speaker’s voice, encoded it in a shared voice-embedding space.
The team then sourced dictionaries in English (using a dataset containing 109 speakers), Spanish (100 speakers), and German (201 speakers) to train the AI models.
The architecture of this AI is based on Facebook’s very own VoiceLoop neural TTS system.
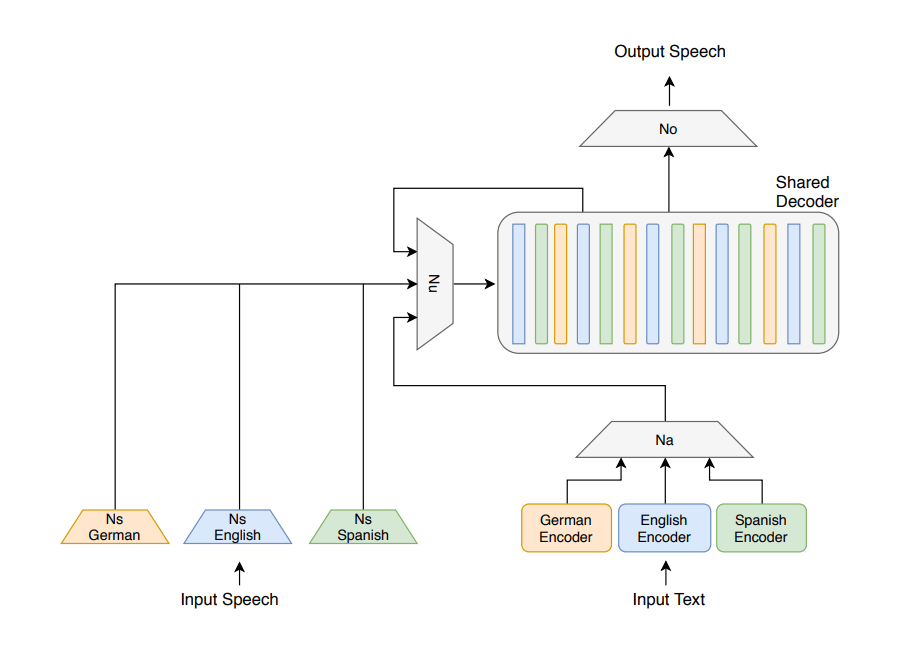
The team then trained the AI in three phases: The first and second, is for the neural network to synthesize multilingual speech. And the third is to optimize the embedding space to achieve “convincing” synthesis.
As a result, the AI system mapped the perceptually distinct units of sound from the source language to the target language, translating the language using a mix of data inputs, including a sample of the speaker’s voice speaking in the source language and text in the target language.
To validate the quality of the generated audio, the researchers used a multiclass speaker identification AI system, as well as human "raters."
Given a ground truth audio sample of the source language and a synthesized sample in the target language,
Here, they were asked to rate the similarity of speakers on a scale of 1 to 5, where a score of 1 corresponded to "different person" and 5 to "same person."
The team achieved the highest self-similarity scores for English, and scores above 3.4 with the AI. As for Spanish and German, the samples were ranked a bit lower.
Still, the researchers concluded that results “show[ed] convincing conversions between English, Spanish, and German.”