As computers become smarter with the use of AI, they have defeated humans at increasingly complex games. These games include chess and Go, as DeepMind's AI AlphaZero has shown.
However, AIs are typically designed for one particular game. Also considered as Artificial Narrow Intelligence (ANI), these "Weak AI" can only do one narrow task.
In this case, they are constructed for one particular game, made to understand how to exploit its properties, and so forth.
According to a paper published by David Silver et al:
"Chess subsequently became a grand challenge task for a generation of artificial intelligence researchers, culminating in high-performance computer chess programs that play at a superhuman level. However, these systems are highly tuned to their domain and cannot be generalized to other games without substantial human effort, whereas general game-playing systems remain comparatively weak."
AlphaZero was developed by DeepMind, a company under the Alphabet umbrella, which also controls Google.
Previously, this particular AI taught itself how to play chess in just 4 hours, before defeating previous chess champion.
This time, the AI has been taught to master the game of Go, chess, and shogi (a Japanese version of chess). And what makes it interesting is that the AI managed to beat beat state-of-the-art programs specializing in these three games, only through reinforcement learning from self-play.
The ability of AlphaZero to adapt to various game rules is a notable step toward achieving a general game-playing system, a step closer to what is called AGI, or a Strong AI.
AlphaZero, which is an improved version of its famous AlphaGo engine, knew nothing about those three games. After feeding basic rules of chess, shogi, and Go, it took the AI 9 hours, 12 hours, and 13 days to learn the games, respectively.
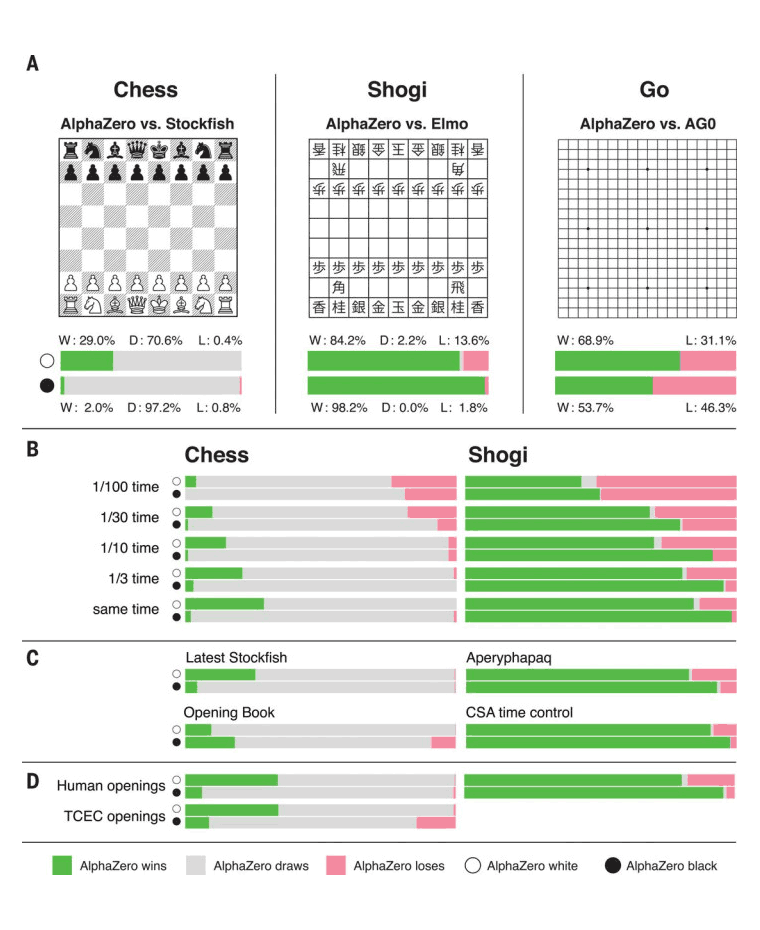
When the AI was then pitted against the world’s best AIs for these games, the results speak for themselves:
Powered by 5,000 of Google's first-generation Tensor Processing Units (TPU), AlphaZero managed to play:
- Chess, and won 155 games, lost 6, and drew the rest out of 1000 matches against Chess master StockFish.
- Shogi, in which it outperformed the world champion software Elmo in 91.2 percent of the games.
- Go, and defeated the original AlphaGo in 61 percent of the games.
AlphaZero won all those games with astonishing results by using a searching method called Monte Carlo Search Tree (MCST) to determine the opponent's next move. This method gave the AI an advantage over its competitors due to its "dynamic and open style."
According to an editorial in Science magazine, chess champion Garry Kasparov praised AlphaZero’s playing style by saying that:
Read: Paving The Roads To Artificial Intelligence: It's Either Us, Or Them