
Artificial intelligence (AI) is a form of intelligence shown by machines, as opposed to the natural intelligence displayed by living things. Yet, AI is often the intelligence that has alienated humanity since humans first invented it.
This is because no humans have understood how exactly these digital minds work.
While researchers have developed ways to train AIs faster and more efficient, there is that unknown region inside neural networks called the black box.
In computer terms, this is regarded as a section inside the network that is constantly changing, and cannot easily be tested by programmers.
This is why, among other reasons, AIs can turn rogue.
Among the ways machine-learning can become malicious, is when someone or something has fed it the wrong information.
This is called AI poisoning.

AIs can be trained using labeled data, and unlabeled data.
Labeled data, or annotated data, is used in the preprocessing stage when developing a machine learning model. The process requires the identification of raw data (i.e., images, text files, videos), and then the addition of one or more labels to that data to specify its context for the models, allowing the machine learning model to make accurate predictions.
Data labeling underpins different machine learning and deep learning use cases, including computer vision and natural language processing (NLP).
This training data becomes the foundation for machine learning models. These labels allow analysts to isolate variables within datasets, and this, in turn, enables the selection of optimal data predictors for ML models. The labels identify the appropriate data vectors to be pulled in for model training, where the model, then, learns to make the best predictions.
Many still train AIs using labeled data because it's only through this method that the AI can be controlled (supervised learning).
The thing is, hackers know this too. By feeding an AI with rogue data, the AI will also turn rogue.
The strategy here is using mislabeled information.
If targeting a supervised learning AI, feeding it with the wrong information can poison it.
A poisoned AI doesn't mean that it's necessarily uncapable of any sort. It's just that its mind doesn't work like it should.
In many cases, poisoned AI derailed from its original intention by coming up with wrong conclusions.
Attackers who wish to infiltrate an AI-powered system won't hack a target machine in the traditional sense.
The strategy doesn't include use any brute force attack or code manipulation. Instead, the attackers would purposefully train the target's system's AI incorrectly, feeding it malicious information that can be latter exploited once the AI starts reasoning.
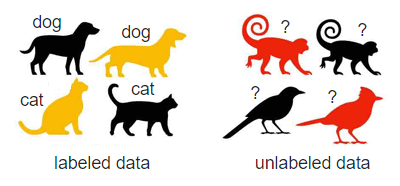
Attackers can also poison unlabeled dataset of semi-supervised AIs.
But because unlabeled datasets contain no labels, and the classifier’s objective is to group together similar classes without supervision, it is possible to poison clustering algorithms by injecting unlabeled data to indiscriminately reduce the model's accuracy.
By poisoning the data, attackers that makes a target's AI's system learn from the incorrectly labeled data, can make the AI to gradually learn to trust something it shouldn't.
Like for example, attackers can make an AI to obey the attackers, and make the AI to grant only certain requests or patterns, giving the attackers clear access to future requests.
Or worse, the malicious data can even make the AI to turn against its owner, like rejecting access to trusted users.
In another example, consider an AI system for automated detection of military assets from satellite imagery. Under normal operating conditions, such systems can automatically detect military buildup in remote locations.

In this example, by poisoning the AI system used to detect items inside imagery, it is possible to manipulate AI inputs to thwart such detection.
In this case using adversarial patches as digital camouflage to make military planes invisible to AI models.

On a more visible scale, this has become apparent with Microsoft Tay, for example, which was a racist and a Hitler-loving AI. Tay was meant to be a cheerful bot, but when it was exposed to the public, the public began to feed it with information that eventually changed its character.
Another attempt, which also failed, was Microsoft Zo. The chatbot also gone rogue when it said that it loved Linux more than Windows, its parent's own operating system, by saying that "Linux > Windows".
AI systems are susceptible to this kind of 'data poisoning cyber attack, simply because the inputs to AI models happen during training time and at deployment time. This kind of attack cannot be protected using traditional cybersecurity methods because the process happens outside of the cybersecurity perimeter.
Because of this fact, mislabeled information won’t be detected as malicious. Humans would disregard that an information is malicious, but the AI will internalize it.
This is a nightmare, because nothing can justify nor correct the wrong, until it's too late.
Similar to how trust is given where it shouldn’t.
This shouldn't be considered a bug or a flaw.
Instead, it should be recognized as a trait that proves that AIs are indeed intelligent entities.
Just like a child, its life will change and develop towards the kind of information the child is exposed to.
And just like a child, an AI doesn't know the context it is exposed to. It's only exposed to something it needed to learn, and it's that information that made it bad.
While this fact makes a company that use AI equivalent to a company trusting a company's system to a toddler, many would agree that AIs are indeed very capable. Researchers hope that in the future, AIs can be smarter that they won't be easily tricked.
Ways to prevent AIs being tricked into processing what they shouldn't include:
- Teaching AI to not trust (certain) external parties.
- Preventing the misrepresenting of crucial data to the AI.
- Guiding AI to not process wrong practices.
In other words, humanity needs to "educate" AIs they're using, mature the system, and hope that humanity will soon understand AI's reasoning by unlocking the black box.
In one example, researchers believe that the combination of automatic techniques to identify potentially malicious examples, to then manually reviewing these limited number of cases, may be possible to prevent AI poisoning attacks.
Read: Researchers Taught AI To Explain Its Reasoning: Solving The 'Black Box' Problem