
Artificial Intelligence, or AI, is an intelligence demonstrated by machines, as opposed to the natural intelligence displayed by living things.
After humans know that computers can be equipped with AI in order for them to understand things beyond their original programming, the boom affected pretty much everything where computers are being used. With AI, computers can be trained to become smarter and smarter.
But the thing about AI is that, the resulting AI is only as smart as the data it has been trained with.
Generally speaking, in the language processing domain, language models with large numbers of parameters, more data, and more training time have been shown to acquire a richer, more nuanced understanding of language.
What this means, the more the data an AI has been trained with, should be able to create a more profound machine intelligence.
This is why Microsoft the tech giant and Nvidia the chipmaker are joining forces to create the largest monolithic transformer language model to date.
The AI model is called the 'Megatron-Turing Natural Language Generation' model, or MT-NLG for short.
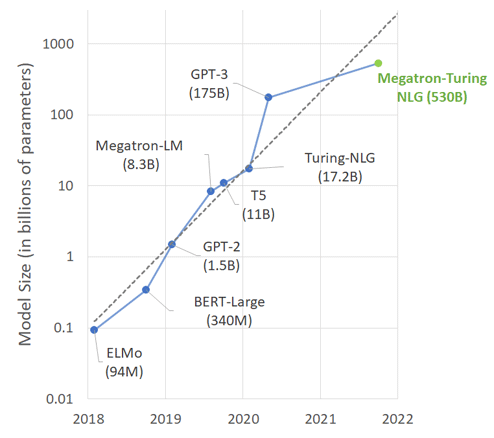
MT-NLG is more powerful than previous transformer-based systems trained by both companies, namely Microsoft’s Turing-NLG model and Nvidia’s Megatron-LM.
The AI model is built to have three time more parameters spread across 105 layers, in order to make MT-NLG much larger and more complex.
In all, Megatron is made from a whopping 530 billion parameters the two companies developed together.
For comparison, OpenAI’s GPT-3 model has 175 billion parameters.
Because bigger is generally better when it comes to neural networks, MT-NLG with that many parameters should have a wider variety of natural language problem-solving abilities, such as auto-completing sentences, question and answering, and reading and reasoning than its predecessors.
Due to the many parameters, MT-NLG can also perform these tasks with little to no fine-tuning.
In other words, the AI can do what it is told with few to zero learning.
The challenge to build language models that have become increasingly larger is that AI researchers and engineers have to come up with new techniques and tricks to train them.
From the quality and the quantity of the data, to coordination.
The researchers have to have the model and its training data stored and processed using numerous computer chips at the same time.
MLT-NLG was trained using Nvidia’s Selene machine learning supercomputer. The system is made up of 560 DGX A100 servers, that contain eight A100 80GB GPUs, each. Selene is also powered by AMD’s EPYC 7v742 CPU processors.
The cost for this kind of machine can go well beyond $85 million.
Because training AI is expensive, even for the likes of Microsoft and Nvidia, efficiency matters.
“We live in a time where AI advancements are far outpacing Moore’s law. We continue to see more computation power being made available with newer generations of GPUs, interconnected at lightning speeds. At the same time, we continue to see hyperscaling of AI models leading to better performance, with seemingly no end in sight,” said the researchers.
“Marrying these two trends together are software innovations that push the boundaries of optimization and efficiency.”
Here, all 4,480 GPUs use NvLink and NVSwitch to connect to one another. Each and everyone of them is capable of operating over 113 teraflops per second.
In comparison, OpenAI’s GPT-3 required an estimated 3.114e23 flops of compute during training, which would theoretically take a V100 GPU server with 28 teraflops capacity over 355 years to train, with a cost of more than $4.6 million.
As for the software, Microsoft and Nvidia used DeepSpeed, a deep learning library containing PyTorch code that allowed the researchers to put together more data across numerous pipelines in parallel. This reduced training time, and allowing the researchers to scale up MLT-NLG. In all, 1.5TB of data was processed to train the model in a process that took a little over a month.
“By combining tensor-slicing and pipeline parallelism, we can operate them within the regime where they are most effective,” Paresh Kharya, senior director of product management and marketing for accelerated computing at Nvidia , and Ali Alvi, group program manager for the Microsoft Turing team, explained in a blog post.
“More specifically, the system uses tensor-slicing from Megatron-LM to scale the model within a node and uses pipeline parallelism from DeepSpeed to scale the model across nodes.
“For example, for the 530 billion model, each model replica spans 280 Nvidia A100 GPUs, with 8-way tensor-slicing within a node and 35-way pipeline parallelism across nodes. We then use data parallelism from DeepSpeed to scale out further to thousands of GPUs.”
With the hardware and software all set, the companies trained MT-NLG largely on a giant dataset known as The Pile.
Compiled by Eleuther AI, a group of AI researchers and engineers leading a grassroots effort to open-source large language models, it is made up of 22 smaller datasets totaling 825GB worth of text scraped off the internet from academic sources (e.g., Arxiv, PubMed), communities (e.g. StackExchange, Wikipedia), code repositories (e.g. Github), and more.
Going beyond that, Microsoft and Nvidia said that they also curated and combined that dataset with filtered snapshots from the Common Crawl, which is a large collection of webpages including news stories and social media posts.
Knowing that most of the dataset comes from all over the web, the large volume of user-generated content include both high- and low-quality information.
And unfortunately for Nvidia and Microsoft, there is no way for them to clean the dataset from toxic content, meaning that MT-NLG can generate offensive outputs that might be biased to certain group, racist or sexist.
“The quality and results that we have obtained today are a big step forward in the journey towards unlocking the full promise of AI in natural language. The innovations of DeepSpeed and Megatron-LM will benefit existing and future AI model development and make large AI models cheaper and faster to train,” Nvidia’s Paresh Kharya and Microsoft’s Ali Alvi wrote in a blog post.
“We look forward to how MT-NLG will shape tomorrow’s products and motivate the community to push the boundaries of natural language processing (NLP) even further. The journey is long and far from complete, but we are excited by what is possible and what lies ahead.”
“Our observations with MT-NLG are that the model picks up stereotypes and biases from the data on which it is trained,” Kharya and Alvi said.
“Microsoft and NVIDIA are committed to working on addressing this problem. We encourage continued research to help in quantifying the bias of the model [...] In addition, any use of MT-NLG in production scenarios must ensure that proper measures are put in place to mitigate and minimize potential harm to users.”