

Create stunning images with just a few words was a dream back in the days before AI.
Thanks to the advancements of the technology, generative AI products that use large language models show how computers can imagine things, and create something out of nothing. Stability AI is one of the notable players in the field.
Having created Stable Diffusion, a revolutionary technology that can generate realistic and high-quality images from any text input, the company steps up to a whole new level with the introduction of Stable Video Diffusion.
Just like what the name suggests, it uses AI to generate videos by reversing a noisy diffusion process that transforms a video into random noise.
Stable Video Diffusion (SVD) a type of generative model that can learn to invert this process and produce videos from images.
Stability AI introduces two AI-powered video generator models, made to serve different purposes.
Today, we are releasing Stable Video Diffusion, our first foundation model for generative AI video based on the image model, @StableDiffusion. As part of this research preview, the code, weights, and research paper are now available.
Additionally, today you can sign up for our… pic.twitter.com/0MbV5DDPt2— Stability AI (@StabilityAI) November 21, 2023
First of, is the standard SVD, which can generate 14 frames of video. The second, is SVD-XT, which can generate 25 frames of video.
The frames per second can be customized between three and 30 frames per second at a resolution of 576×1024.
Typically, videos the AIs create span between 2 to 4 seconds, in MP4 format.
"This state-of-the-art generative AI video model represents a significant step in our journey toward creating models for everyone of every type,” the company said.
The company introduced the two AI models for research purposes only, and those who wish to the video diffusion have to contact Stability AI to request waitlist access.
This happens because the AIs are somewhat experimental.
"The generated videos are rather short (four seconds), and the model does not achieve perfect photorealism," explained Stability AI.
"The model may generate videos without motion, or very slow camera pans. The model cannot be controlled through text. The model cannot render legible text. Faces and people in general may not be generated properly."
On the company’s Hugging Face page, it admits that Stable Video Diffusion is still limited.
Regardless, "we have found these models surpass the leading closed models in user preference studies," said Stability AI.
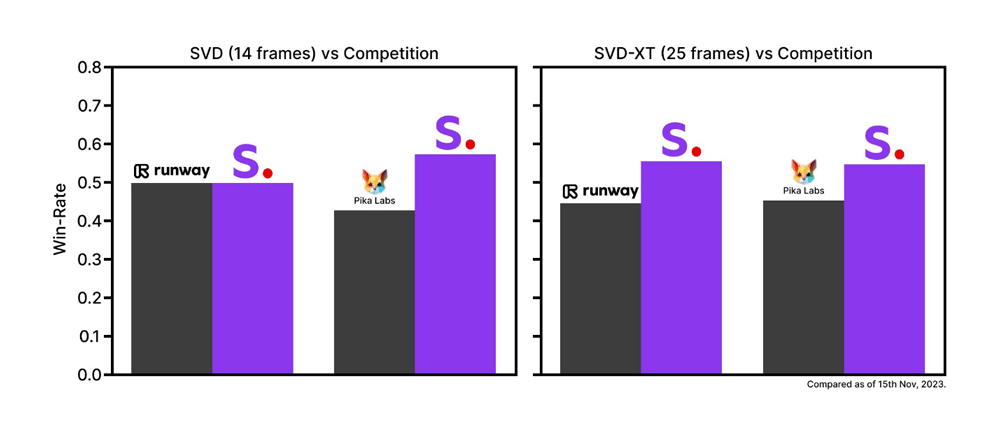
According to reports, the text-to-video tool was trained on a dataset of millions of videos which were then fine-tuned on a smaller set.
For its video model, Stability AI said that it used "publicly available" data, meaning that it only used data that can be found on the internet.
Stable Video Diffusion will be looking to compete with the likes of Pika, which pretty much does the same thing.
These AIs, including Runway's, started a video diffusion revolution on the web, where people are using the tools to bring their favorite memes to life.
With the tools, users are simply uploading memes, which are literally snapshot of reality pulled out of context, and reimagine them.
And the results speak for themselves.
Some can be spooky, some are outrageous, and some are indeed interesting.
Stability AI's Stable Video Diffusion is free to use and open-source accessible through its GitHub repository.