
Websites on the web can collect a lot of data from search engine crawlers. The information can be compiled inside a log file, something that many webmasters overlook.
Most if not all websites use analytics tool track and report website traffic. In real-time, the tool can show detailed information about activities the website is experiencing.
This information can be a treasure when used properly.
First of all, these analytics tools generate information about visitors and how they behave. They also show which pages are the most popular, and under what keywords do visitors visit their pages, and many other metrics.
Second, the tools also give insight that can be used for SEO purposes and other site/content improvements.
However, if webmasters have long obsessed with crawl budget, for exmple, this is where server's log file can help.
This file records everything that goes in and out of a website, and can also provide information about search engine crawlers' activities, server errors, as well as how well the spam filter is working, among others.
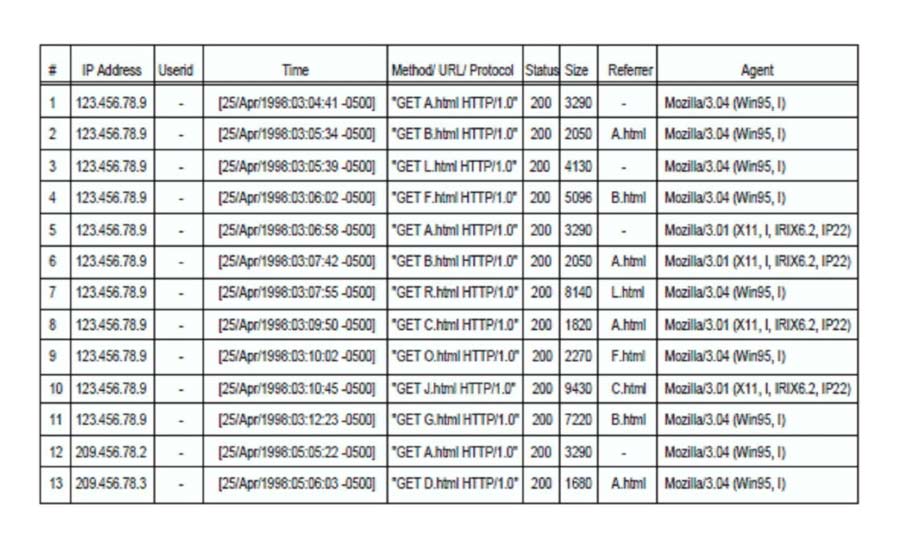
However, webmasters should not worry too much about their crawl budget.
While Google and other search engines do limit their bots' crawling activities to save resources on both itself and the website it crawls, they still crawl to see if anything needs to be fixed.
The more popular a website is, the more traffic it generates, the happier search engine bots in visiting their pages.
The most useful information the log file can give, is the error codes the site has whenever present. The file can also show duplicate contents, or improper redirect process.
To understand search engine crawlers' behavior, the things to consider include:
- The search engines that crawl the website.
- The URLs that are crawled most often.
- The content types that are crawled most often.
- The status codes returned.
Order the log by the number of requests, evaluate the ones with the highest number to find the pages with the highest priority.
Webmasters may want to group the data into segments so they can get the bigger picture. This would allow them to spot the trends they might have missed when looking at individual URLs.
Webmasters should also segment the data by user-agent to pinpoint weaknesses in pages for different search engines.
Having doing the above, it's time to monitor the log for behavior changes over time.
Whenever a website is online, it will generate continuous stream of log. Over time, the log can be fully occupied with data from crawlers' activities.
Webmasters may want to take a closer look at crawl rates because search engines crawlers' activities may adapt to the website's speed, link structure and uptime.
Webmasters should also know that crawlers that visit their website aren't always the good ones.
Some crawlers can be spambots and scrapers.
While webmasters can block these bots from ever visiting their site, smarter bad bots can masquerade their identity by pretending to be Googlebot user agent, for example.
To verify if a web crawler is really a legitimate bot or not, webmasters can run a reverse DNS lookup and then a forward DNS lookup.

Log analysis is a must, especially for larger websites that get a lot of traffic.
Webmasters can combine their own log files with the ones generated by third-party analytics tools, including Google Analytics, for example. Properly analyzing the data should give webmasters a lot of great hidden insight.
The best time to check the log file is during the period where the website/its server experienced significant changes.
In normal conditions, webmasters may want to check the log file on a monthly basis, or weekly if the site is more popular.
Understanding this should help webmasters better understand the situation their site is experiencing.
Logs also hold valuable information that can help webmasters pinpoint technical errors before they become a larger problem.
Server logs can help webmasters to understand the situation of their site better, based on data that analytics tools don't properly show on their own.