
Artificial Intelligence can be smart to an extent that some are better than humans in specific fields. But AIs can be fooled quite easily.
For example, image-recognition AIs can be fooled using adversarial examples. Using this method, specially created noise or other invisible or near-invisible manipulations can fool AIs into believing what's not.
What can happen with image-recognition AIs, can also happen on natural language processing AIs (NLPs).
Because AIs have become more capable, NLPs have become increasingly capable of generating human-like text. With AIs becoming more widespread, NLPs have attracted many malicious actors who would use them to produce misleadinging media.
This is why researchers at Computer Science and Artificial Intelligence Laboratory (CSAIL), MIT, have developed a system called 'TextFooler' to trick AI models, like the ones used by Google Assistant, Siri and Alexa.
The system can be used to train AIs to better catch spam or respond to people's offensive language.
TextFooler too is a type of adversarial system.
But in this case, the researchers designed to to attack NLP models, so their creators can understand their flaws.
To make this happen, TextFooler alters an input sentence by changing some words, but without changing its meaning or grammar. After that, it attacks an NLP model to check how it handles the altered input text classification and entailment (the relationship between parts of the text in a sentence).
Changing text without changing its meaning can be difficult.
To do this, TextFooler must first look for the important words in a sentence that carry heavy ranking weightage for a particular NLP model. After that, it looks for words that are synonymous.
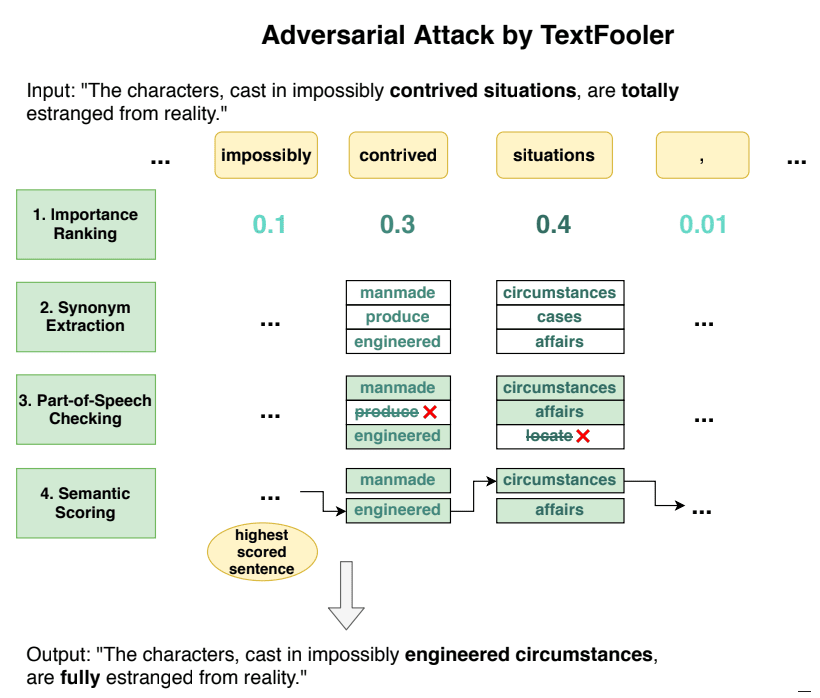
TextFooler then replaces the words to fit the sentence perfectly.
TextFooler can repeat the process of replacing existing words with semantically similar and grammatically correct words until the targeted NLP's prediction is altered.
Researchers said that the system successfully fooled three existing models, including BERT, which is Google's popular open-sourced language model that has a relatively robust performance compared with the other models tested.
By changing only 10% of the text in a sentence, the researchers said that TextFooler achieved high levels of success.
According to a MIT post, Di Jin, the lead author on the paper about TextFooler, he said that tools based on NLP should have effective defense approaches to protect them from manipulated inputs:
“The system [TextFooler] can be used or extended to attack any classification-based NLP models to test their robustness. On the other hand, the generated adversaries can be used to improve the robustness and generalization of deep learning models via adversarial training, which is a critical direction of this work.”
By making the project open source on GitHub, Jin and his team at MIT hope that TextFooler can be used to train text-based AI models in the areas of email spam filtering, hate speech flagging, or “sensitive” political speech text detection.