

What makes computers so capable is because it can process a lot of information at the same time.
With more advances hardware, researchers can run more advanced software. And as computers become smarter due to better hardware and software, smarter AIs should make computers capable of deciding things on their own.
This is crucial in AI development, especially when that development aims to create a smarter AI that is supposedly called the next-generation AI that is no longer a "narrow" AI (ANI).
AI is certainly the future of technology, and it's becoming one of the most important topic that has been debated and argued more than many times.
And this time, a team of scientists from Google Research, the Alan Turing Institute, and Cambridge University have unveiled a multimodal transformer for AI, which can be considered a state-of-the-art AI that can 'hear' and 'see' at the same time.
Having an AI doing two things simultaneously is considered the next step of AI development.
Read: Paving The Roads To Artificial Intelligence: It's Either Us, Or Them
Powerful AI systems, like OpenAI's GPT-3 for example, has been considered the benchmark of transformer AIs.
At its core, GPT-3 can process and categorize data from a specific kind of media stream.
The thing is, it cannot do more than one thing at a time.
So if an AI is meant to do multiple things at one, under the state-of-the-art paradigm, it requires several models running concurrently.
Researchers need a model that has been trained on videos, and another model that has been trained on video clips. This is necessary because algorithms necessary to process different types of audio are typically different than those used to process video.
This time however, Google and its partners managed to create a multimodal system that can handle tasks simultaneously.
The researchers were also able to design the AI to outperform all existing state-of-the-art models that are focused on a single task.
On the researchers research paper:
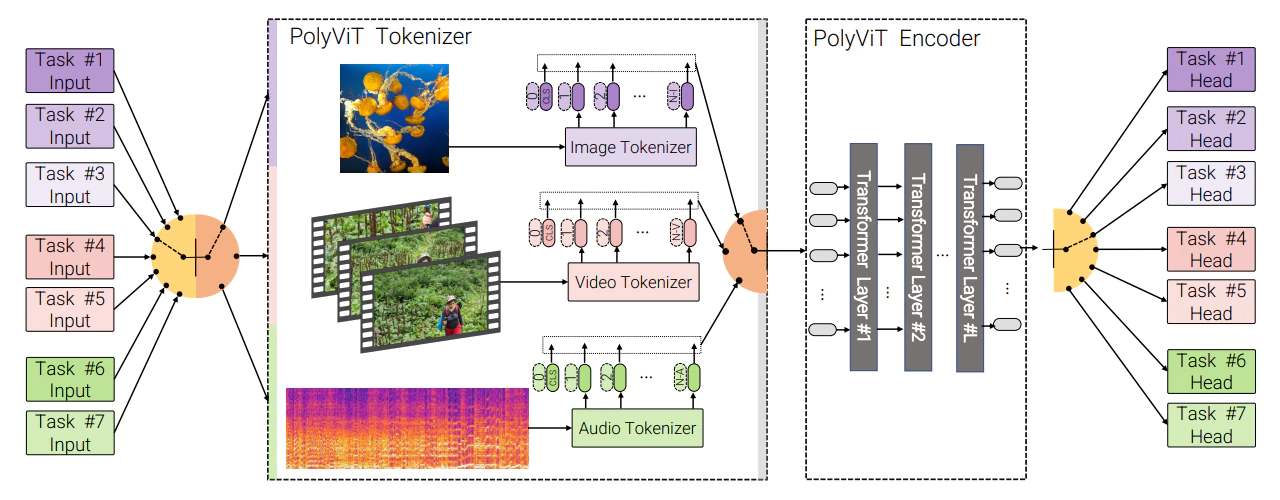
The researchers that called their system 'PolyViT' continued to explain that:
"Moreover, we show that co-training is simple and practical to implement, as we do not need to tune hyperparameters for each combination of datasets, but can simply adapt those from standard, single-task training."
This advancement can be a huge deal, considering that AIs have had difficulties in understanding how to accomplish two different tasks at the same time.
The researchers said that they've managed to achieve the state-of-the-art results on three video and two audio datasets, "while reducing the total number of parameters linearly compared to single-task models."
At least at this time, the system has a number of limitations. For example, the researchers didn't train the AI on large-scale upstream datasets. And while it is versatile, the AI does not improve inference time as it still processes a single task at a time.
Read: Google Has An AI Language Model That Is 6 Times Larger Than OpenAI's GPT-3