

AI researchers agree that increasing parameters is one of the main keys to improve the capabilities of machine learning algorithms.
Parameters are part of AI models, in which the models learn from historical training data. In natural language processing AIs for example, the more the parameters the AI models learned from, the more sophisticated and complex languages the AI models can understand.
For example, OpenAI’s GPT-3 is known as one of the largest AI models ever trained.
Created by researchers at OpenAI, the AI model was trained with a staggering 175 billion parameters. With that many parameters, the more virtual knobs and dials users and researchers can twist, tune and adjust to achieve the desired outputs.
As a result, the more they will have the control of what the output will be.
Models trained from GPT-3 can create reviews of itself, went wild on Reddit to write many large, deep posts very rapidly, help people create new blog post ideas, becomes an impersonator for famous people, and many more.
Google is one of the main players in the AI field. Feeling a bit left behind, the company leaps forward, with its researchers saying that they have developed and benchmarked techniques they claim enabled them to train a language model containing more than a trillion parameters.
This AI model can achieve up to 4 times speedup over T5-XXL, the previously largest Google-developed language model. And with more than a trillion parameters, it's around 6 times larger than GPT-3.
On the researchers' paper, it is said that:
"We address these with the Switch Transformer."
"We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs"
Detailing their work, the researchers said that large-scale training is an effective path toward powerful models. With simple architectures, but backed by large datasets and parameter counts, the researchers know that they can surpass more more complicated algorithms.
Simply put, the researchers at Google have figured out a way to make the model itself as simple as possible, while squeezing in as much raw compute power as possible to make the increased number of parameters possible.
But what's to highlight here, is that the 'Switch Transformer' is capable of using “sparsely activated” technique that uses only a subset of a model’s weights, or the parameters that transform input data within the model in order to save cost.
The big idea here is that with enough raw power, the better compute-use techniques can be made possible, which in turn make it possible to do more with less compute.
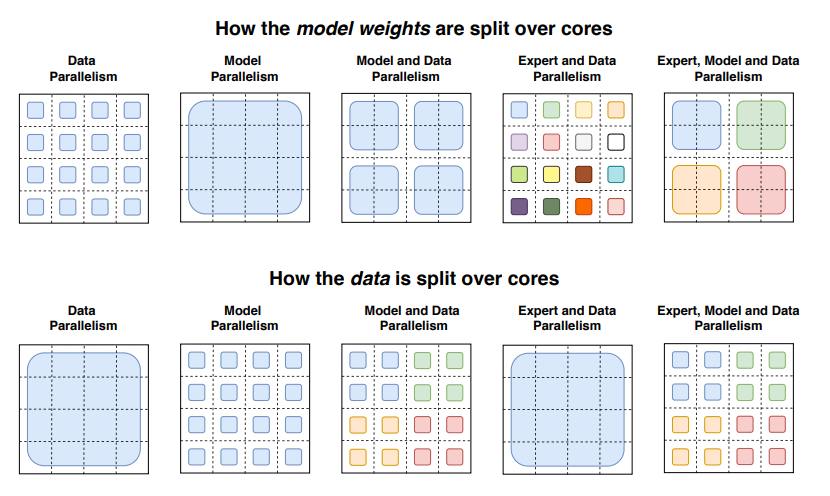
To do this, the Switch Transformer was built on a mix of multiple experts (or models) specialized in different tasks, all of which are working inside a larger model and have a “gating network” to choose which models to consult for any given data.
"We simplify Mixture of Experts to produce an architecture that is easy to understand, stable to train and vastly more sample efficient than equivalently-sized dense models. We find that these models excel across a diverse set of natural language tasks and in different training regimes, including pre-training, fine-tuning and multi-task training."
"These advances make it possible to train models with hundreds of billion to trillion parameters and which achieve substantial speedups relative to dense T5 baselines."
Using this approach, the Switch Transformer can efficiently use hardware designed for dense matrix multiplications, such as GPUs and Google’s tensor processing units (TPUs).
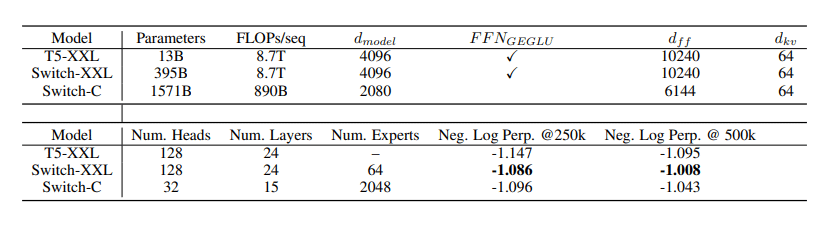
The researchers claim their 1.6-trillion-parameter model can work with 2,048 experts (Switch-C).
In the researchers’ distributed training setup, their models split unique weights on different devices so the weights increased with the number of devices but maintained a manageable memory and computational footprint on each device.
On their research, the team pretrained several different Switch Transformer models using 32 TPU cores on the Colossal Clean Crawled Corpus, and a data set that is worth 750GB scraped from Reddit, Wikipedia, and other web sources.
They tasked the models with predicting missing words in passages where 15% of the words had been masked out, as well as other challenges, like retrieving text to answer a list of increasingly difficult questions.
"We cannot fully preserve the model quality, but compression rates of 10 to 100 times are achievable by distilling our sparse models into dense models while achieving ~30% of the quality gain of the expert model.”
In future work, the researchers plan to apply the Switch Transformer to “new and across different modalities,” including image and text.
The researchers believe that model sparsity can confer advantages in a range of different media, as well as multimodal models.
While this feat is certainly an achievement, the researchers’ work didn’t take into account the impact of these large language models in the real world.
Further reading: AI Ethics Pioneer Fired From Google Over Her Paper That Highlighted Bias In AI