

The AI field was quite boring that it rarely send ripples that disrupt other industries, until OpenAI kickstarted a hype.
When it introduced ChatGPT, it quickly wowed pretty much everyone who uses it. With the ability to respond like a human being, but with the knowledge of the entire internet, the technology sent other tech companies into frenzy.
In response, Google created Bard.
While it botched at first, the company managed to make it a worthy competitor, especially when the company began integrating it to various Google apps and services, among others.
The thing is, despite being powerful and knowledgeable, generative AIs have limitations.
One of which, is the amount of words it could process during a single go.
In the industry, the interaction between users and a generative AI product is measured and discussed based on "tokens" and "context windows."
Whereas a token is a unit that might represent a word, or a bit of a word, a number or something similar, a context window is the space where users of an AI product can input a question, or text, or any other format the AI supports, so the AI can analyze and respond.
OpenAI's GPT-3.5 model has a context length of 16,000 tokens, while its successor, the GPT-4, has 32,000. The chatbot Claude from Anthropic has a context window of up to 100,000 tokens, which works out roughly to 75,000 words
This number is huge for humans, especially because the human brain is limited to the amount of neurons and the size of the skull. But for computers, which processing power are only limited to the their hardware and software, both of which improve as time passes, there should be ways to increase that number.
In a research paper from a Google researcher Hao Liu, UC Berkeley, along with Databricks CTO Matei Zaharia and UC Berkeley professor Pieter Abbeel, it's revealed a novel way to help AI churn in way more data.
The researchers suggests a novel way to remove a major restrictions on AI models.

In the paper titled "Ring Attention with Blockwise Transformers for Near-Infinite Context" (PDF), the co-author explained that the method is a riff on the original Transformer architecture that revolutionized AI in 2017 and forms the basis of ChatGPT and all the new models that have come after that, including Meta's LlaMA and LLaMA 2, as well as others.
The idea is that these AI models crunch data in a way that requires GPUs to store various internal outputs and then re-compute them before passing this along to the next GPU.
This process consumes a lot memory, and no matter how much memory is added, the AI will deplete it.
In the end, the bottleneck limits how much input an AI model can process.
No matter how fast the GPU is, there's a memory bottleneck.
"The goal of this research was to remove this bottleneck," the co-author said.
With what's called the "Ring Attention," AI models can process millions of words, the researchers said.
To put it into perspective, one million words is equivalent to more than a dozen of standard-length novels, or a few thousand web pages.
With Ring Attention, AI can ingest a lot more than that, at a time.
With it, people can change human-computer interaction, and significantly improve the ability of AI products.
The approach essentially creates a kind of ring of GPUs that pass bits of the process along to the next GPU while simultaneously receiving similar blocks from their other GPU neighbor, and so forth.
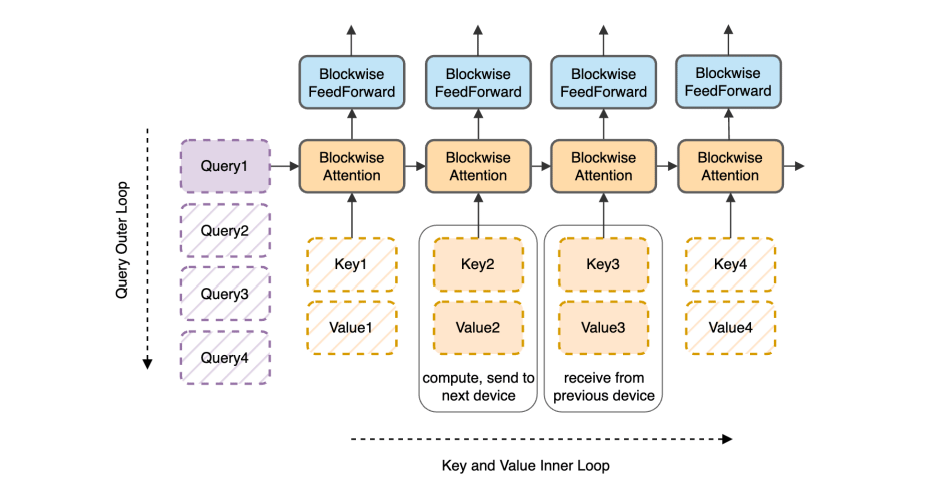
"This effectively eliminates the memory constraints imposed by individual devices," the researchers wrote, referring to GPUs.
As a result, an AI model "could read an entire codebase, or output an entire codebase," Liu said.
"The more GPUs you have, the longer the context window can be now. I'm GPU poor, I can't do that. The big tech companies, the GPU rich companies, it will be exciting to see what they build."
In an example, the authors said that for a 16,000 token context window, and with a 13 billion parameter AI model that relies on 256 Nvidia A100 GPUs, the context length is limited to 16,000.
But with the Ring Attention approach, that same setup would be able to handle a 4 million token context window.
A significant improvement to say the least.