
Thanks to the viral sensation of OpenAI's talkative chatbot, it's now an arms race of generative AIs.
The AI field was dull and quiet, and the buzz it created mostly happened within its own field, and rarely reach far beyond its own audience. But when OpenAI introduced ChatGPT as a AI chatbot tool, the internet was quickly captivated.
This is because the AI is able to do a wide range of tasks, including writing poetry, technical papers, novels, and essays.
And when others, like Microsoft, started embedding the technology into Bing and Edge, despite with a few issues, and that even the underdog Opera wants to use it to power parts of its web browser, Google started to worry.
It was a "code red".
Google is known for its conservative approach on the development and deployment of large language models ("LLMs"). But following the hyped ChatGPT, Google was too ambitious that it deliberately failed in its first announcement of Google Bard, in a move that cost the company $100 billion.
With others jumping into the bandwagon, Meta, the company formerly known as Facebook, is now into the game.
And that is by announcing what it calls the 'LLaMA.'
LLaMA (Large Language Model Meta AI) achieves results competitive with the best currently released models while being smaller & more efficient — increasing accessibility to this technology for more researchers working on this important subfield of AI across the globe.
— Meta AI (@MetaAI) February 24, 2023
What stands for 'Large Language Model Meta AI', it essentially an AI for research and academic use.
"This release is a part of Meta’s continued commitment to open science and transparency," said Meta AI, in a Twitter tweet and a Facebook post.
As part of Meta’s commitment to open science, LLaMA is "designed to help researchers advance their work in this subfield of AI."
To do this, LLaMA provides research communities that don't have access to large amounts of infrastructure to study these models, in order to "further democratizing access in this important, fast-changing field."
LLaMA is considered a smaller foundation models, meaning that the large language model requires far less computing power and resources.
The AI behind the technology has been trained on a large set of unlabeled data, which makes it ideal for fine-tuning for a variety of tasks.
In its argument, large language models which are behind natural language processing (NLP) systems, have been trained with billions of parameters. As a result, they have shown new capabilities and show abilities that can even go beyond context and their original programming.
"They are one of the clearest cases of the substantial potential benefits AI can offer at scale to billions of people," Meta AI said.
The thing is, researchers tend to have limited access to this kind of technology, because of the resources that are required to train and run such large models.
"This restricted access has limited researchers’ ability to understand how and why these large language models work, hindering progress on efforts to improve their robustness and mitigate known issues, such as bias, toxicity, and the potential for generating misinformation," Meta AI argued.
Because of this LLaMA was trained to purposefully become a smaller model.
But trained on more tokens, or pieces of words, Meta managed to fine-tune the system for specific potential product use cases.
In comparison, OpenAI's GPT-3 was trained with 175 billion parameters and 300 billion tokens, whereas LLaMA was trained with only 65 billion parameters, but with a staggering 1.4 trillion tokens.
Unlike ChatGPT or Bard, Meta's LLaMA is not a chatbot. It's more similar to GPT-3.5 and LaMDA, both of which power the ChatGPT and Bard conversational AI applications, respectively.
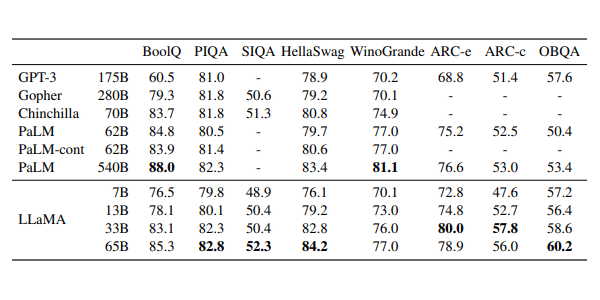
According to the company's research paper, its LLaMA-13B is superior to GPT-3 OpenAI (175B), and its top of the line LLaMA-65B is comparable to Chinchilla70B from DeepMind, and PaLM-540B from Google.
Just like other large language models, LLaMA works by taking a sequence of words as an input and predicts a next word to recursively generate text. But unlike others, LLaMA here is designed to work with 20 different languages.
Just like others, LLaMA shares issues, like hallucination and traits of emotions.
But as a foundation model, LLaMA is designed to be versatile and can be applied to many different use cases.
"We believe that the entire AI community — academic researchers, civil society, policymakers, and industry — must work together to develop clear guidelines around responsible AI in general and responsible large language models in particular. We look forward to seeing what the community can learn — and eventually build — using LLaMA," said Meta AI.
The introduction of LLaMA marks Meta's growing foray in the LLM arms race.
But most importantly, it also marks a shift in focus. Previously, CEO and founder Mark Zuckerberg was really into the metaverse. But this time, he is no longer that ambitious.
Read: Following OpenAI ChatGPT's Hype, Meta's Mark Zuckerberg Quietly Dumps His Metaverse Ambition
























































































































































































































































































































































































