

AI is the hype, and it's starting to get itself everywhere.
After the likes of GPT-2, and its successor, the GPT-3, to DALL·E and then DALL·E 2, things are not stopping.
Quickly speeding up, it's Google's Imagen and Stable Diffusion, and the ChatGPT, among others.
With AI-generated arts and deepfaked test appearing everywhere, this time, Microsoft is having a go.
And that is by introducing what it calls 'VALL-E', which is similar to DALL-E but for voices.
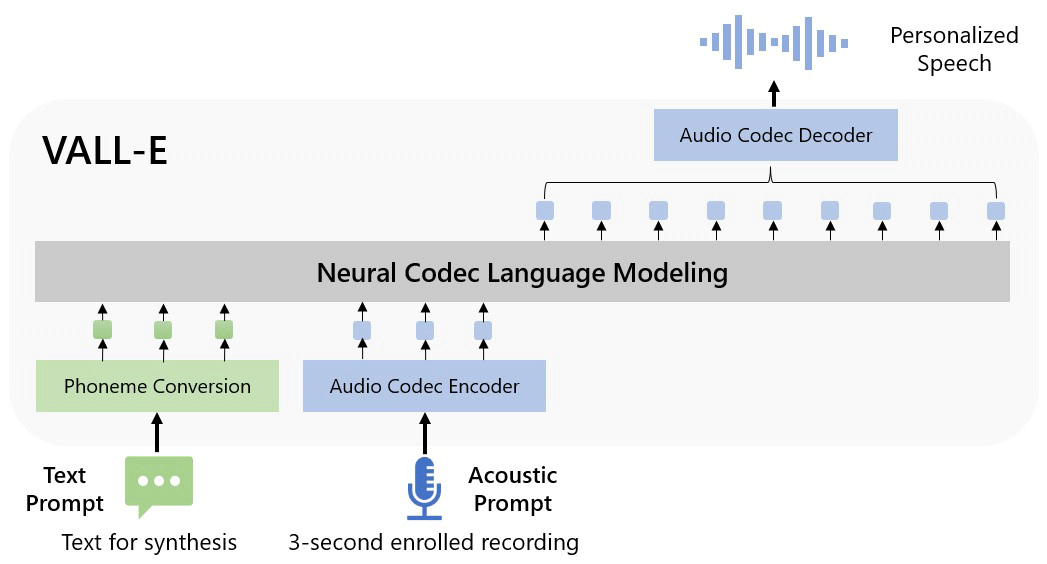
The AI is able to replicate any voice after listening to just three seconds of audio.
The AI is able to accomplish the feat by easily matching emotion and tone, something many voice AI tools struggle with
Microsoft have announced their AI "VALL-E"
Using a 3-second sample of human speech, it can generate super-high-quality text-to-text speech from the same voice. Even emotional range and acoustic environment of the
sample data can be reproduced. Here are some examples. pic.twitter.com/ExoS2VWO6d— Tuvok @ NaughtyDog (@TheCartelDel) January 7, 2023
Once it learns a specific voice, VALL-E can synthesize the audio of that person saying anything, and do it in a way that attempts to preserve the speaker's emotional tone.
The AI is also capable of demonstrating in-context learning abilities, and could also replicate words it had never heard.
All that in just three seconds of learning.
According to its GitHub page, it is reported that VALL-E is capable of prompt-based TTS (text-to-speech), follows context, and doesn’t need pre-designed acoustics or any structural engineering to deliver its audio sample.
To be able to do this, the team at Microsoft trained VALL-E on roughly 60,000 hours of English speech data from more than 7,000 speakers, mostly pulled from LibriVox public domain audiobooks.
This, is "hundreds of times larger than existing systems."
On their research paper (PDF), the researchers described VALL-E as a "neural codec language model", built from a technology called EnCodec, which Meta announced in October 2022.
The way it works, include analyzing how a person sounds, to then break down that information into discrete components (tokens). And with EnCodec, it uses training data to match what it "knows" about how that voice would sound if it spoke other phrases outside of the three-second sample.
Because VALL-E generates discrete audio codec codes from text and acoustic prompts, this makes VALL-E unlike any other text-to-speech methods that typically synthesize speech by manipulating waveforms
As a result of this, the researchers said that VALL-E could be used for high-quality text-to-speech applications, speech editing where a recording of a person could be edited and changed from a text transcript (making them say something they originally didn't), and audio content creation when combined with other generative AI models like GPT-3.
While this technology certainly sounds impressive, the implication can be scary.
When Microsoft announced VALL-E, the AI has not been made available to the public.
And when the time comes, there is doubt that the AI would have to deal with numerous controversies, security, social, and ethical concerns, to say the least.
For starters, the it's a concerning development for voice actors, as well as anyone who could be tricked into thinking they're on a call with a relative who desperately needs their personal details.