
Computers don't have imagination. But AI does, the longer the technology is trained with images of the world.
OpenAI experimented with text-to-image generator, and created the 'DALL·E', which it considers the 'GPT' for images. Then, it created 'DALL·E 2', which takes the image-generation AI to an eerie level.
Google has a similar AI it calls 'Imagen'. The technology is a hype, that even TikTok is developing one for itself.
But most of the time, the technology that underlie the AI, is proprietary. If not, its use is restricted, and isn't publicly available for everyone.
This time, another similar technology wants to disrupt the hype.
It's called 'Stable Diffusion', and it's open-source.
What this means, the public can use it, for free.
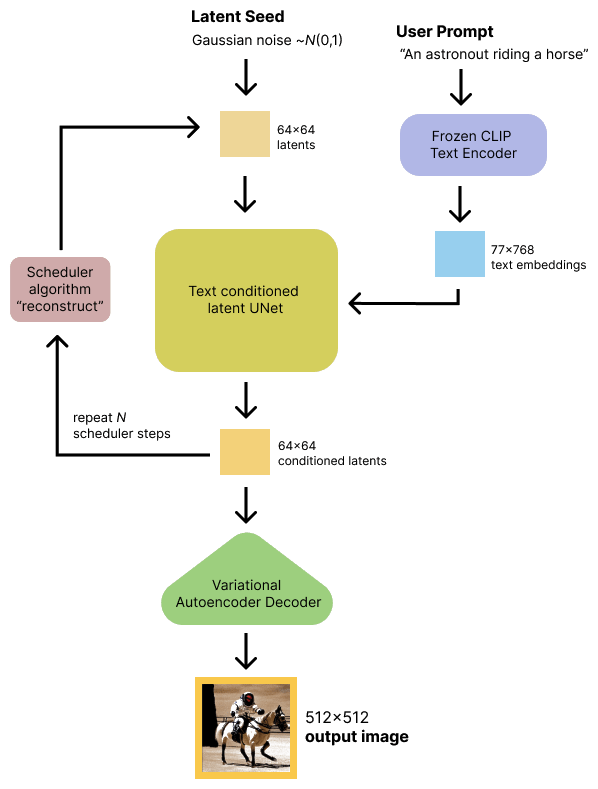
Created by Stability AI, the model was trained on image data set using hundreds of high-end GPUs.
Before releasing it to the public, it is said that Stable Diffusion cost around $600,000 to train. During the training process, the model associates words with images using a technique called CLIP (Contrastive Language-Image Pre-training), which was invented by OpenAI.
When using it, users of the pre-trained AI model can give it a prompt.
The AI then goes to work by generating a photorealistic 512x512 pixel images depicting the scene described in the prompt.
The technology uses an image generation technique called latent diffusion models (LDMs).
Unlike other popular image synthesis methods such as generative adversarial networks (GANs) and the auto-regressive technique used by DALL·E, Stable Diffusion in using LDMs allows it generate images by iteratively "de-noising" data in a latent representation space, to then decode the representation into a full image.

LDM was developed by the Machine Vision and Learning research group at the Ludwig Maximilian University of Munich.
Just like DALL·E, the Stable Diffusion model can support several operations.
For example, it can be given a text description of a desired image and generate a high-quality that matches that description. It can also generate a realistic-looking image from a simple sketch plus a textual description of the desired image.
Earlier public release of the software had limited release, and was focused to only those in the research community.
But this time, Stability AI has made the project open source, allowing anyone to download and run Stable Diffusion on consumer-level hardware. Beside text-to-image generation, the model also supports image-to-image style transfer as well as upscaling. Along with the release, Stable AI also released a beta version of an API and web UI for the model called DreamStudio.

According to Stable AI:
To showcase what this technology is capable of, Katherine Crowson, lead developer at Stability AI, has shared many images on Twitter.
Many users of Stable Diffusion have also publicly posted examples of generated images.

Due to its ability and capacity, many people have become worried that this kind of technology can disrupt existing arts and artists.
Because the AI learned from data that is publicly available by just seeing it, Stable Diffusion has absorbed the the many styles of many living artists. As a result, some of then have spoken out forcefully against the technology.
And this became more apparent, when Stable Diffusion was released.
This is because the technology managed to create an AI-generated artwork that won first prize in an art competition at the Colorado State Fair.
At this though, the AI does have some limitations.
For example, it cannot "understand" the relationship between colored pixels at a high level. It also cannot understand that a human, for example, has two hands, and not two heads or six fingers.