

With the continuous developments in AI, researchers achieve milestone after milestone, with next achievement more intriguing than the former.
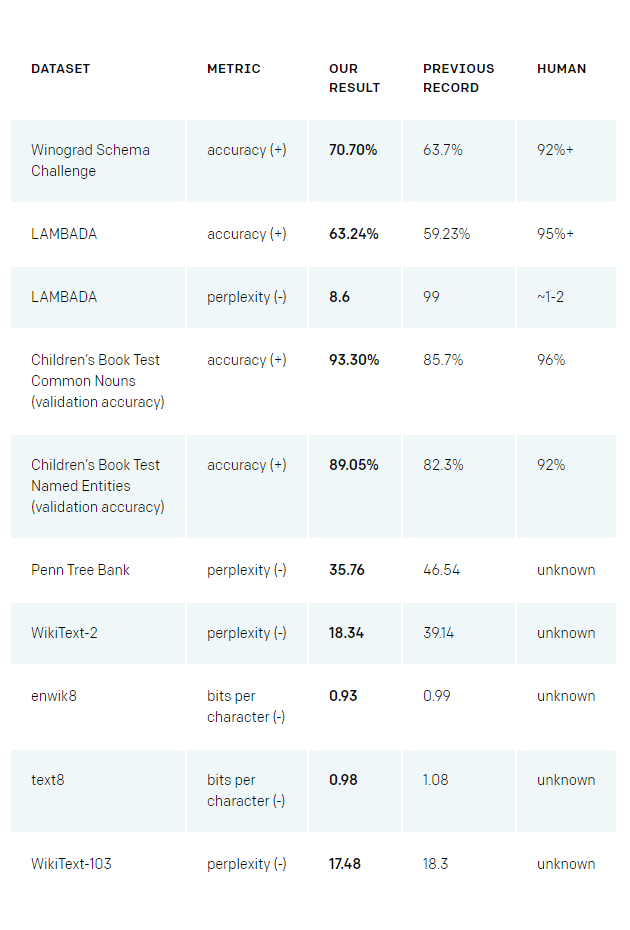
OpenAI is an artificial intelligence research company. And here, the company's researchers said that they have developed a large-scale unsupervised language model which generates coherent paragraphs of text, achieves state-of-the-art performance on many language modeling benchmarks.
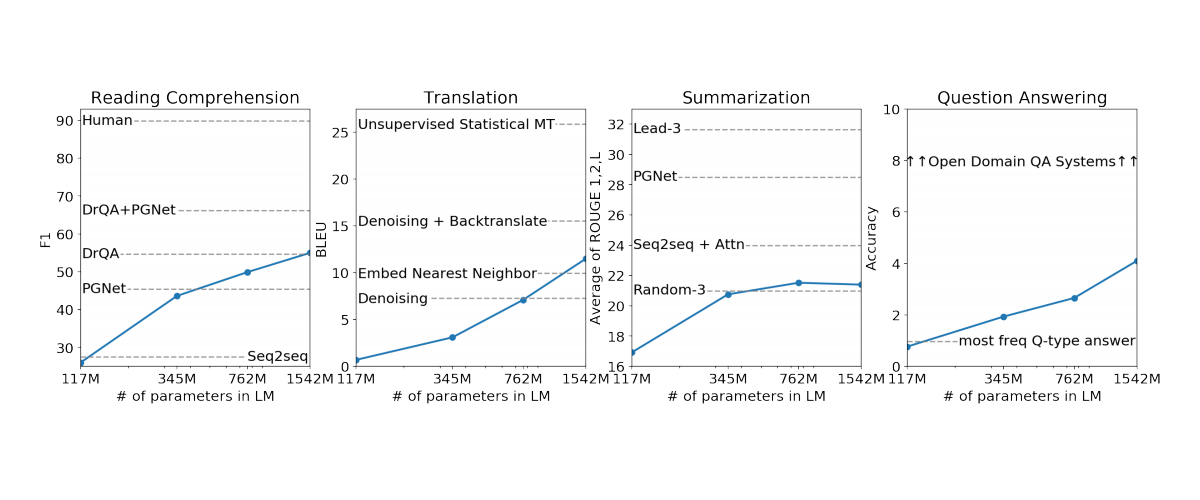
The company continued by saying that the AI "performs rudimentary reading comprehension, machine translation, question answering, and summarization — all without task-specific training."
In blog post, the samples suggest that the AI is indeed an extraordinary step forward.
It's capable in producing text rich with context, nuance and even humor. It’s so good in doing what it's told to do, that OpenAI said that it isn't releasing its code to the public because the researchers think it could be misused.
The AI is called the 'GPT-2'.
This successor of 'GPT' has been trained with more than 8 million web pages worth more than 40GB of internet text data.
When the researchers at the company tasked the AI with predicting the next word based on how those words have been used on the websites it read, the algorithm was capable in generating passages of text that "feel close to human quality."
The results were coherent than past attempts researchers have made to build AI with contextual knowledge of language.
It should be noted that the model wasn't trained on any of the data specific to any of these tasks and was only evaluated on them in a final test. This process is known as 'zero-shot' setting.
In one example, the researchers tasked the AI with an opening of a fictional news article about scientists who discovered unicorns.
"In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English," the researchers gave the AI to process.
After that, the algorithms created a narrative story, including some made-up quotes by the scientists, saying that:
"The scientist named the population, after their distinctive horn, Ovid’s Unicorn. These four-horned, silver-white unicorns were previously unknown to science."
"Now, after almost two centuries, the mystery of what sparked this odd phenomenon is finally solved."
"Dr. Jorge Pérez, an evolutionary biologist from the University of La Paz, and several companions, were exploring the Andes Mountains when they found a small valley, with no other animals or humans. Pérez noticed that the valley had what appeared to be a natural fountain, surrounded by two peaks of rock and silver snow."
The paragraphs continues, showcasing how well the AI can make up imaginary stories only after given a little heads up.
Nevertheless, the AI is not perfect.
The researchers have observed some failure modes, such as repetitive text, world modeling failures (such as writing something impossible, like fires happening under water), and unnatural topic switching.
The AI seems to be capable in generating stories if it is already familiar with the context. Since it learns from the web, it should know how to create stories on topics that are well-represented (like Brexit, Miley Cyrus, Lord of the Rings, and so on). But if it is tasked with highly technical or esoteric types of content, the model can perform poorly.
Still, the AI has a lot of potential. "Overall, we find that it takes a few tries to get a good sample,." OpenAI's post reads.
In good ways, the AI can be used to create AI writing assistants, helping the development of more capable dialogue agents, unsupervised translation between languages and better speech recognition systems.
But in the days where fake news, deepfakes and other forms of misinformation are plaguing social media and the overall internet, making this AI loose for developers to use can be dangerous.
"It could be that someone who has malicious intent would be able to generate high quality fake news," explained David Luan, OpenAI’s vice president of engineering.
This includes, and not limited to:
- Generating misleading news articles.
- Impersonating others on the web.
- Automate the production of abusive or faked content to post on social media.
- Automate the production of spam/phishing content.
"Due to concerns about large language models being used to generate deceptive, biased, or abusive language at scale, we are only releasing a much smaller version of GPT-2 along with sampling code. We are not releasing the dataset, training code, or GPT-2 model weights," Open AI explained.
The model of this AI has been documented on a research paper called Language Models are Unsupervised Multitask Learners, and the smaller version of this GPT-2 can be found on its GitHub page.