
Google has been in the tech industry for decades, and has also ventured into developing AIs to not only improve its products, but to also experiment with the technology.
For more than many times, researchers have showed how AIs can make computers increasingly smarter. With AIs, computers can be trained to understand the things beyond their own programming, in many ways that can even surprise their own creators.
Among the many things AIs can do, is creating images based on text input.
The idea here, is allowing users to give it any descriptive text, and let the AI turn that into an image.
OpenAI, for example, has what it calls the 'DALL·E', which is essentially the 'GPT' for images. And building on that AI, OpenAI has announced its successor, the 'DALL·E 2'.
This time, Google has announced a competitor, and its name is 'Imagen'.
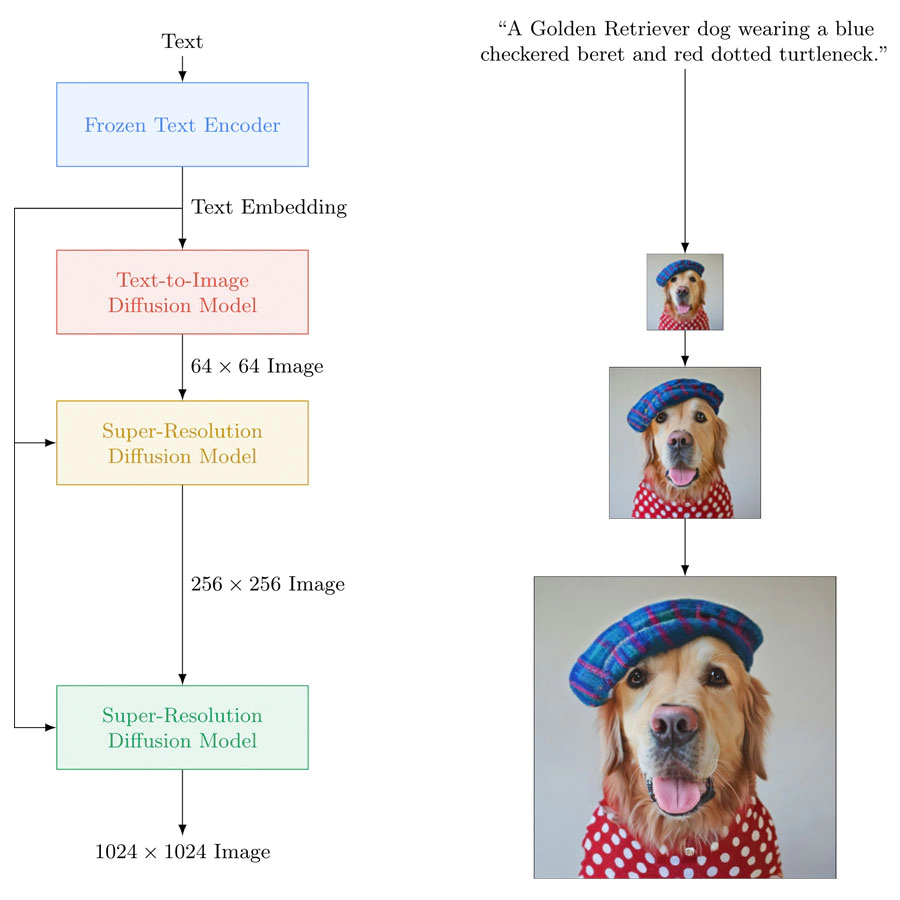
According to Google, Imagen is a diffusion AI model, created by the Google Brain Team at Google Research.
What it does, is offering "an unprecedented degree of photorealism and a deep level of language understanding."
Just like OpenAI's two DALL·Es, Imagen is able to turn text into images.
"Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation," the researchers said in their paper.
While Imagen is pretty much similar to DALL·E, the biggest difference here is that, Google's version of the AI is able to create more realistic images.
Google shared several examples of text prompts and the resulting images created by the AI on its Imagen website.

It's worth noting though, that the examples provided by Google are curated. As such, these may be the best of the best images that the model created.
But regardless, it's outstanding to see how far AIs have developed.
Imagen consists of a text encoder that maps text to a sequence of embeddings and a cascade of conditional diffusion models that map these embeddings to images of increasing resolutions
The text-to-image model requires powerful semantic text encoders to capture the complexity and compositionality of arbitrary natural language text inputs. For Imagen, the text encoders were trained on paired image-text data are already the standard, but the team leaped forward by introducing a way to effectively train the AI using text only corpus.
"Language models are trained on text only corpus significantly larger than paired image-text data, thus being exposed to a very rich and wide distribution of text," the researchers said.
After that, the team introduced DrawBench, a comprehensive and challenging evaluation benchmark for the text-to-image task.
"DrawBench enables deeper insights through a multi-dimensional evaluation of text-to-image models, with text prompts designed to probe different semantic properties of models," the researchers explained. "These include compositionality, cardinality, spatial relations, the ability to handle complex text prompts or prompts with rare words, and they include creative prompts that push the limits of models’ ability to generate highly implausible scenes well beyond the scope of the training data."
It's through this DrawBench, that extensive human evaluation shows that Imagen outperforms other other previous methods.

Just like OpenAI's DALL·E, Imagen is not available to the public.
At this time at least, Google doesn't think the AI is suitable as yet for use by the general public for a number of reasons.
First and foremost, the reason is because the text-to-image model was trained on large datasets that are scraped from the web and are not curated, which introduces a number of problems.
"While this approach has enabled rapid algorithmic advances in recent years, datasets of this nature often reflect social stereotypes, oppressive viewpoints, and derogatory, or otherwise harmful, associations to marginalized identity groups," the researchers wrote.
"While a subset of our training data was filtered to removed noise and undesirable content, such as pornographic imagery and toxic language, we also utilized LAION-400M dataset, which is known to contain a wide range of inappropriate content including pornographic imagery, racist slurs and harmful social stereotypes."

Because of this, Imagen inherited the "social biases and limitations of large language models" and may depict "harmful stereotypes and representation."
The team's findings indicated that the AI does encode social biases, including the tendency to create images of people with lighter skin tones and to place them into certain stereotypical gender roles.
Additionally, the researchers also noted that at its initial state, there is the potential for misuse if Imagen were made available to the public as it is.
"In future work we will explore a framework for responsible externalization that balances the value of external auditing with the risks of unrestricted open-access," the researchers wrote.























































































































































































































































































































































































