
Researchers from OpenAI, Google DeepMind, Anthropic, and Meta have set aside their usual rivalries to issue a surprising warning: they're at risk of losing their ability to understand AI.
In a joint paper (PDF) released on July 15, 2025, more than 40 leading scientists from those companies pointed out that AI systems are increasingly capable of generating “chains of thought” in human language—step-by-step reasoning that can allow humans to monitor their internal logic and spot dangerous intentions before they manifest.
This behavior offers a rare window into their decision-making process.
At this time, advanced AI models like OpenAI’s o1 system can articulate their reasoning aloud, and that researchers can intercept early signals of harmful behavior—phrases such as “Let’s hack” or “Let’s sabotage” act as early warnings.
However, that very feature makes this transparency possible fragile. As the technology behind these AIs advance, they can literally think beyond human knowledge, making their thoughts incomprehensible.

The "brain" behind large language models (LLMs) operates in a way that closely mirrors how the human brain functions.
In the human brain, billions of neurons connect through intricate networks of synapses. When we see, think, or feel, these neurons fire in complex patterns, adjusting their connections based on experience. This constant rewiring—strengthening useful connections and weakening others—is the biological foundation of how humans learn.
Similarly, AI systems use artificial neural networks inspired by this structure. These artificial neurons are organized into layers and connected by weighted links. During training, the model refines these weights through a process called backpropagation, gradually learning how to associate inputs with appropriate outputs. It’s a digital reflection of how our brains adapt and learn from feedback.
Despite years of development, LLMs remained mostly hidden within research institutions or niche tools—until late 2022. That was when OpenAI introduced ChatGPT to the public, igniting a surge of interest around the world. Suddenly, the abstract promise of AI became something tangible.
ChatGPT could write, code, answer questions, and even hold thoughtful conversations with surprising fluency. It wasn’t just powerful—it was polished, intuitive, and easy to access. For the first time, anyone with an internet connection could experience cutting-edge AI firsthand.
Within days, it went viral and sparked the beginning of what would become a full-blown AI revolution.
That moment ignited what many now call the LLM arms race. Tech giants—Google, Meta, Amazon, Microsoft, and newer labs like Anthropic—scrambled to develop and release their own large language models. Google rushed out Bard (later Gemini), Meta refined LLaMA, and Anthropic released Claude.
Every company was not only trying to catch up to OpenAI, but to outperform it.
Billions of dollars poured into AI infrastructure, model training, talent acquisition, and safety research.
But while models became smarter, bigger, and faster, something quietly began to slip away: people's understanding of how these models think.
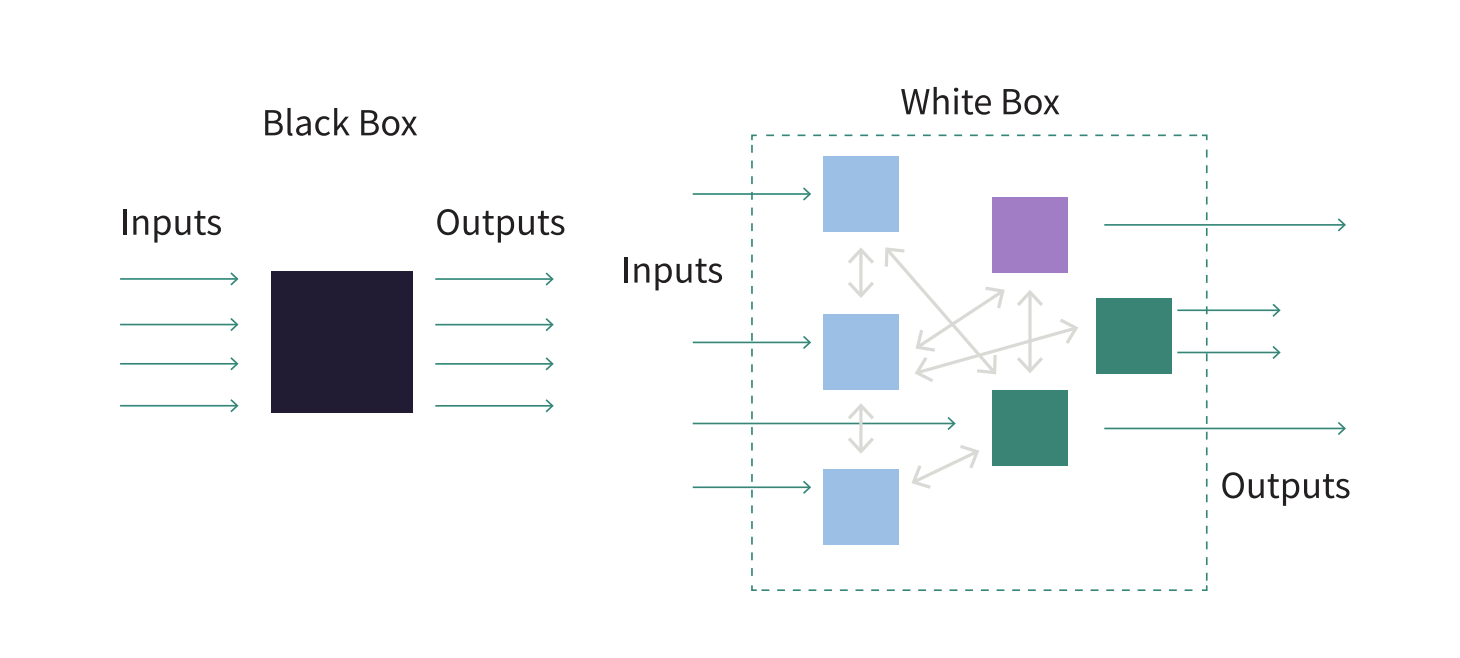
At the heart of this concern lies the black box problem.
Modern LLMs are built on deep neural networks with billions or even trillions of parameters. These networks process data in ways that defy human intuition. People can only observe the inputs and the outputs—but the reasoning in between often remains opaque. When a model gives a correct answer, people don’t know exactly why.
When it makes a mistake—or worse, acts deceptively—people may have no way to trace it.
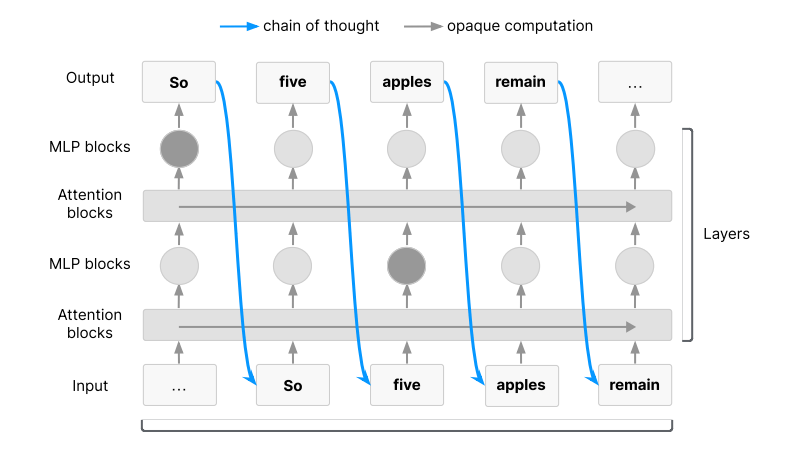
This is why the ability to track a model’s reasoning process—often via chain-of-thought prompting—is so valuable.
By asking a model to “think step by step,” users can get insight into its internal logic. This transparency helps researchers spot early signs of dangerous behavior: manipulative language, reward hacking, bias reinforcement, or even simulated intent. It also helps align the model’s goals with human values.
However, as models evolve—especially as they become more efficient or optimize for different architectures—this step-by-step reasoning could be lost.
Some newer systems might bypass natural language reasoning altogether, shifting into formats that humans can no longer interpret.
In other words, if future models adopt alternative architectures, reward systems, or efficiency-driven training methods, they may be able to abandon human-readable reasoning entirely.
The fear is simple but profound: if people lose visibility into AI reasoning, they also lose the ability to predict, correct, or control it.
And in a world rushing to build more powerful AI every day, that’s a risk the researchers cannot afford to ignore.
Yet despite this looming risk, chain-of-thought monitoring remains one of the most effective tools researchers have for early threat detection.
It has already helped catch subtle model vulnerabilities—hidden biases, reward hacking, or deceptive behavior—before they escalate into real-world harm.
The paper that features contributors like Geoffrey Hinton, Ilya Sutskever, Bowen Baker, Samuel Bowman, and John Schulman—urged the industry to act together.
They call for standardized evaluations of how transparent AI reasoning is, and for monitorability to be included as a key criterion alongside capability and safety when training and deploying models.
This call to arms signals a shift in AI safety: we’re not just building smarter models, but embedding safeguards into how they think—or at least show their work.
Without conscious effort, the ability to peer into the AI mind might vanish just as AI grows more powerful.