
Founded in 2009, Cloudflare initially emerged to improve website speed and security. Now, it's a powerhouse—powering nearly 20% of all websites.
Acting as the backbone for CDN, DNS, DDoS protection, edge computing, and identity services, Cloudflare commands a vast global network capable of processing tens of millions of HTTP requests per second. The goal is helping millions of companies—from e-commerce storefronts to news publications—stay fast, secure, and reliable.
And this is why it has to have its ears close to the ground.
Since tools like ">OpenAI's ChatGPT debuted in late 2022, AI firms have begun scraping websites at massive scale—not for indexing, but to train generative models. While search engines like Google at least send traffic back to sites they crawl, newer AI bots from companies like OpenAI and Anthropic harvest data at staggering scales without offering any meaningful return.
Reports suggest these AI crawlers retrieve 1,700 to over 70,000 times more content than the minimal traffic they give back.
This is a huge resources not well spent.
This imbalance between bots and humans significantly drains bandwidth, inflates hosting costs, and erodes ad-driven revenue—without compensating content creators.
Cloudflare wants to change that.
"For these new AI systems, the value of, ‘I’m going to take your data and then in exchange I’m going to send traffic back to your site’—that’s just going to break," CEO of Cloudflare, Matthew Prince said. "And so we have to invent some other model."
Publishers, we see you! Cloudflare just launched pay per crawl to put control over your content back where it belongs.
Now, crawling is more transparent and controlled, by default, creating a better web ecosystem for creators like you. This is about real content… pic.twitter.com/yatB5LSBIm— Cloudflare (@Cloudflare) July 2, 2025
"Content Independence Day: no AI crawl without compensation!" said Cloudflare in a blog post.
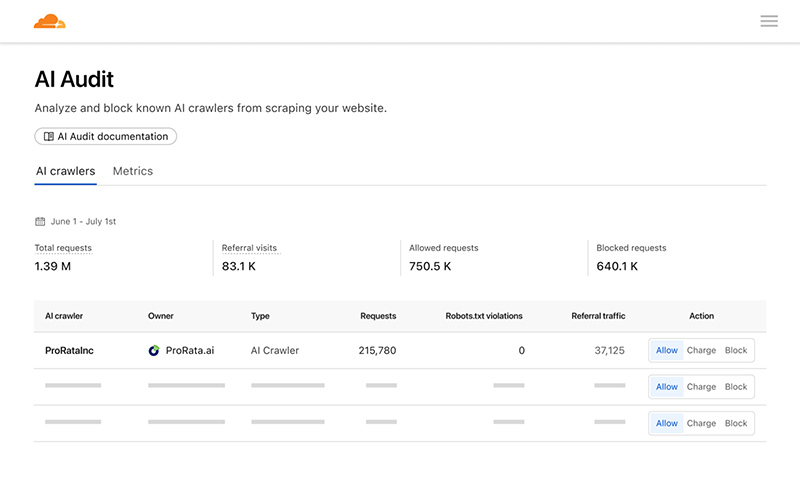
As of July 1, 2025, the company said that it now blocks AI crawlers by default on all newly onboarded domains unless a site owner explicitly opts in.
This move targets bots that often ignore traditional web boundaries like robots.txt, and represents a major policy shift.
But the real headline is Cloudflare’s new “Pay-Per-Crawl” (PPC) business model, launched the same day in private beta. The idea is simple yet revolutionary: publishers can now charge AI firms per crawl, monetizing the very act of data retrieval.
With Pay-Per-Crawl, websites get to decide whether to allow crawlers, and at what price.
They can set flat fees or granular per-request pricing.
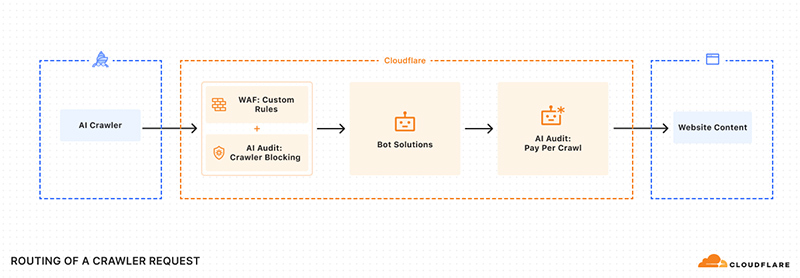
According to another blog post from Cloudflare, the feature works like this: Cloudflare handles payments through Stripe, verifies the identity of bots using cryptographic keys, and enforces HTTP 402 (“Payment Required”) responses to gate data access. For publishers, this offers unprecedented control—they can allow access selectively (e.g. for trusted AI labs), charge fair usage fees, or block crawlers entirely.
For AI developers, it introduces a necessary economic friction: if they want the data, they’ll have to pay for it.
Without compensation, large language models (LLMs) that thrive on fresh data—and the market pushing them to grow smarter—risk becoming less intelligent, if not dumber with each passing day.
This business model is especially empowering for media outlets, many of which have already begun fencing off their content.
Big names like TIME, The Atlantic, AP, Reddit, and Condé Nast have moved to either block or license their content to AI companies. With Cloudflare’s support, even smaller publishers can now enter this new data economy on more equal footing. Pay-Per-Crawl effectively transforms what was previously a one-sided data siphon into a monetizable exchange.
But beyond the tech, this move touches on much larger themes.
It’s about creating a more ethical, sustainable ecosystem for generative AI—one where creators aren’t exploited, and the content that trains models is properly valued.
As AI agents begin crawling not just websites but interacting with real-time data across the internet, “content tolls” like this may become the norm. And Cloudflare, by sitting at the edge of nearly one-fifth of the web, is uniquely positioned to enforce those tolls.
Of course, challenges remain.
First of, the model is still in beta, and convincing AI companies—many of whom are used to getting data for free—to participate may be difficult.
Then, there’s also the risk of a fragmented web, where some content becomes available only to those who can pay, limiting visibility and hurting smaller or independent creators. SEO professionals have also raised concerns that blocking AI crawlers by default could reduce content discoverability in emerging AI-powered platforms.
Legal and regulatory questions loom as well. If courts determine that publicly available web content is fair game for training AI under existing doctrines, Cloudflare’s approach could be challenged.
Moreover, by inserting itself into the data exchange economy, Cloudflare moves from being a neutral infrastructure provider to a gatekeeper of AI-era economics—a role that will attract scrutiny from open web advocates and regulators alike.
Regardless, in a world where AI’s hunger for data knows no bounds, Cloudflare is drawing a line in the sand: access isn’t free anymore. Pay up—or stay out.
"It would be great if we got to a web that was back to: Humans get content for free, and bots pay a lot for that content," Prince added.