

Google parent company Alphabet’s DeepMind has what it calls AlphaZero, an AI system that could teach itself how to master board games, like chess, shogi, and the game Go.
In each case, the AI was capable of defeating world champions, fair and square. AlphaGo learned the games from scratch, but winning the games were possible because the AI had the advantages of knowing the rules of the games, before it was tasked at playing them.
What this means, the AI learned how to play by self-play, but had previously embedded the knowledge about the games.
In a pursuit to create machine learning technology that outpaces AlphaGo, the team at DeepMind developed 'MuZero', which is similar to AlphaGo that is capable of playing and winning board games by learning from scratch, but can also learn the rules by itself.
In other words, the AI plays by having no idea about the games, before turning itself into a pro.
According to the researchers:
This tree-based search is where data structure is used for locating information from within a set, withing a learned model.
Using this method, MuZero can predict the quantities most relevant to game planning, such that it achieves great performances on 57 different Atari games, as well as matching the performance of AlphaZero in Go, chess, and shogi.
Both AlphaGo and MuZero use reinforcement learning, which is a technique that rewards AI agents toward goals.
But specifically for MuZero, the researchers pursued an approach focusing on end-to-end prediction of a value function, where an algorithm is trained so that the expected sum of rewards matches the expected value with respect to real-world actions.
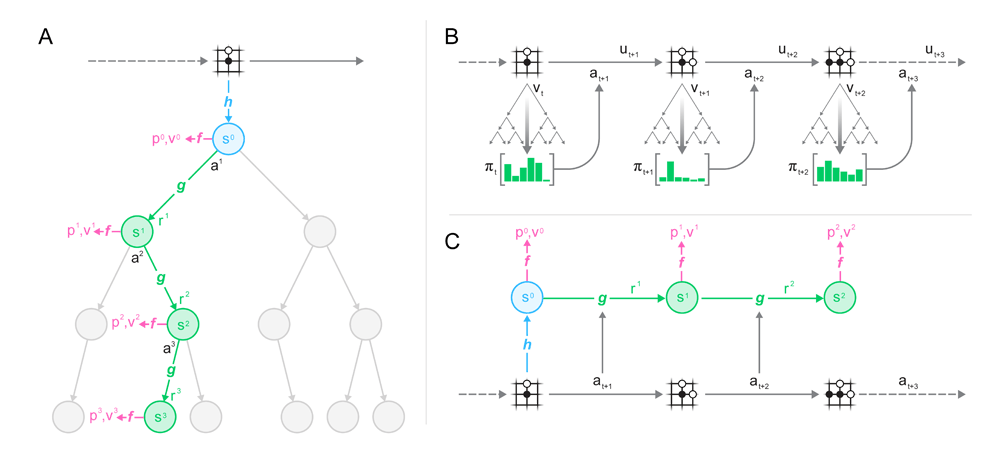
The system has no semantics of the environment state but simply outputs policy, value, and reward predictions.
To do this, MuZero must first receive observations of the board games. In this case, it needs to see images of a Go board or an Atari screen, to then transform them into a hidden state.
This hidden state is then updated iteratively using a process that receives the previous state and a hypothetical next action. And at every step, the model can predict the policy, the move to play, the value function, the predicted winner and so forth.
Another way of saying it: MuZero can internally invent game rules or dynamics that lead to accurate planning.
Then, the team applied MuZero to the classic board games as benchmarks for challenging planning problems, and to all 57 games in the open source Atari Learning Environment as benchmarks for visually complex reinforcement learning domains.
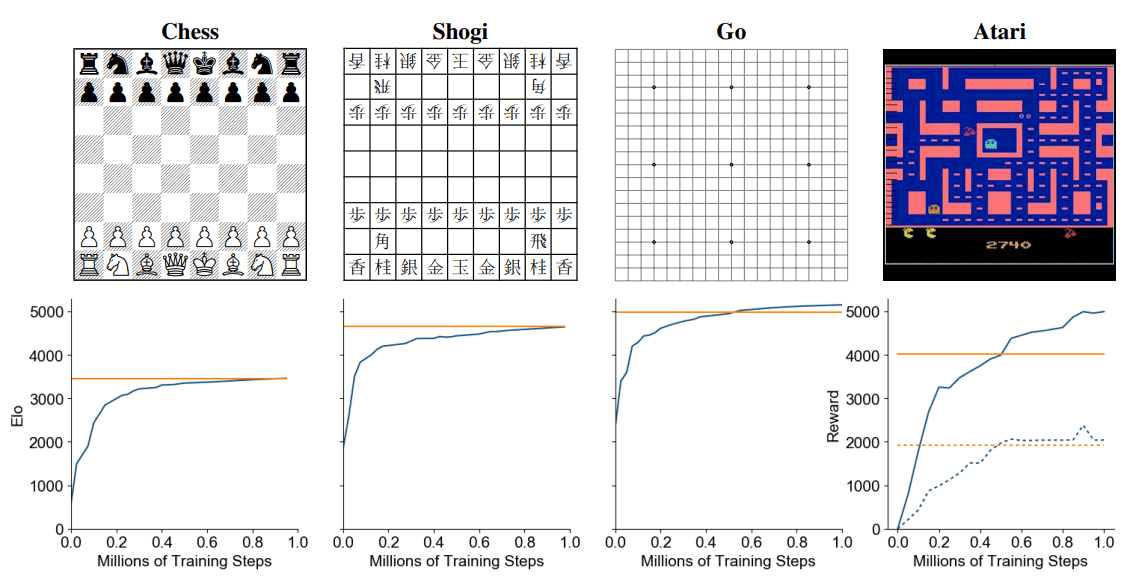
After training the AI agents for five hypothetical steps and a million mini-batches of size 2,048 in board games and size 1,024 in Atari (800 simulations per move for each search in Go, chess, and shogi and 50 simulations for each search in Atari), MuZero slightly exceeded the performance of AlphaZero despite using less overall computation.
The researchers said that it was possible for it to achieve this feat because the AI might have gained a deeper understanding of its position:
"In this paper we have introduced a method that combines the benefits of both approaches. Our algorithm, MuZero, has both matched the superhuman performance of high-performance planning algorithms in their favored domains – logically complex board games such as chess and Go – and outperformed state-of-the-art model-free [reinforcement learning] algorithms in their favored domains – visually complex Atari games."
As for Atari, MuZero achieved a new state of the art for both mean and median normalized score across the 57 games, outperforming the previous state-of-the-art method (R2D2) in 42 out of 57 games and outperforming the previous best model-based approach in all games.
And with further optimizations for greater efficiency, the team reported that MuZero managed a 731% median normalized score compared to 192%, 231% and 431% for previous model-free approaches IMPALA, Rainbow, and LASER, respectively, while requiring substantially less training time.
This achievements, according to the researchers, makes MuZero capable of paving the way for learning methods in a host of real-world domains, particularly those lacking a simulator that communicates rules or environment dynamics.
“Planning algorithms … have achieved remarkable successes in artificial intelligence … However, these planning algorithms all rely on knowledge of the environment’s dynamics, such as the rules of the game or an accurate simulator,” wrote the scientists in a preprint paper. “Model-based … learning aims to address this issue by first learning a model of the environment’s dynamics, and then planning with respect to the learned model.”
Read: Paving The Roads To Artificial Intelligence: It's Either Us, Or Them