
With just one sentence, a new world can spring into existence, proving that AI consistently amazes—because it’s both artificial and undeniably intelligent.
It took the technology just a few years, before being capable of generating text responses, to then create 2D imagery, to then creating fully 3D videos. Google, the tech giant, is taking this a bit further with what it calls the 'Genie 2.'
DeepMind Technologies Limited, also known by its trade name Google DeepMind, is an AI research laboratory which serves as a subsidiary of Google after it was acquired.
This time, the company shows that generative AI not only can create still images or just videos, because Large Language Models can also be made to create an entire new world from nothing.
All it takes is just a text prompt.
With Genie 2, Google has reached a groundbreaking milestone: the ability to generate playable 3D game worlds instantly.
Introducing Genie 2: our AI model that can create an endless variety of playable 3D worlds - all from a single image.
These types of large-scale foundation world models could enable future agents to be trained and evaluated in an endless number of virtual environments. →… pic.twitter.com/qHCT6jqb1W— Google DeepMind (@GoogleDeepMind) December 4, 2024
In a blog post, Google DeepMind said that:
From Nvidia's GET3D to OpenAI's Point·E and Shap·E to Intel's LDM3D among many others, AI has came a long way before really understanding the real world.
For DeepMind, games play a key role in its various researches.
From pioneering Atari gameplay to groundbreaking achievements like AlphaGo, which bested the world’s top Go player, and AlphaStar, which attained Grandmaster status in StarCraft II, games have always been central to the evolution of the company’s AI innovations.
And Genie 2 here can generate a "vast diversity of rich 3D worlds."
And the result is more than just astounding.
If you can imagine it, you can play it in Genie 2
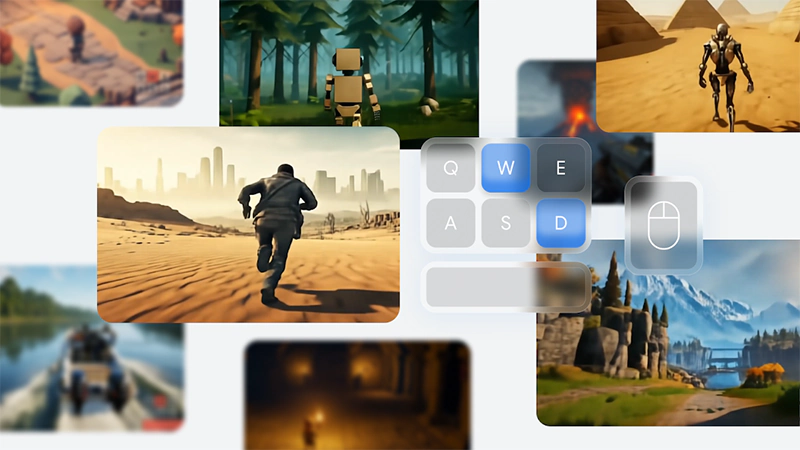
Our foundation world model is capable of generating interactive worlds controllable with keyboard/mouse actions, starting from a single prompt image
So proud to have been part of this work led by @jparkerholder and @_rockt https://t.co/6ZgLganccc pic.twitter.com/elZjK4NKZa— Harris Chan (@SirrahChan) December 5, 2024
Examples of worlds created by Genie 2 from a single image. Playable with keyboard and mouse for up to 1 min, up to 720p.
Made by the Genie team @GoogleDeepMind pic.twitter.com/Ka1l74jkDV— Alexandre Moufarek (@amoufarek) December 5, 2024
Genie 2 is a very impressive model and the perspective of generating endless, unique worlds is incredibly exciting! Collaborating with the team has been a truly fun and inspiring experience https://t.co/6ESF6g1Hx1
— Fabio Pardo (@PardoFab) December 5, 2024
Genie 2, which is the successor to Genie, which was released earlier this 2024, was trained on videos.
This is to make the AI capable of simulating object interactions, animations, lighting, physics, reflections, and the behavior of NPCs.
From just a single image and text description, Genie 2 can generate an interactive, real-time scenes.
But what makes it on a league on its own is that, it create worlds where users can take actions like jumping and swimming by using a mouse or keyboard.
The AI can also generate diverse trajectories from the same starting frame, which means it is possible to simulate counterfactual experiences for training agents, capable of remembering parts of the world that are no longer in view and then rendering them accurately when they become observable again, create content on the fly with different perspectives, create objects that can interacted with, animate characters, and more.
"As we show, Genie 2 could enable future agents to be trained and evaluated in a limitless curriculum of novel worlds. Our research also paves the way for new, creative workflows for prototyping interactive experiences," said DeepMind.