
AI researchers agree that increasing parameters is one of the best ways to improve the capabilities of machine learning algorithms.
Parameters are part of AI models, in which the models learn from historical training data. In natural language processing AIs for example, the more the parameters the AI models learned from, the models should become more sophisticated, in which the models should be able to understand more complex languages.
For example, the GPT-3 is known as one of the largest AI models ever trained.
Created by researchers at OpenAI, the AI model was trained with a staggering 175 billion parameters. With that many parameters, the more virtual knobs and dials users and researchers can twist, tune and adjust to achieve the desired outputs.
As a result, the more they will have the control of what the output will be.
Models trained from GPT-3 can create reviews of itself, went wild on Reddit to write many large, deep posts very rapidly, help people create new blog post ideas, becomes an impersonator for famous people, and many more.
Google is one of the main players in the AI field.
Feeling a bit left behind, earlier this 2021, the company said that its researchers have developed and benchmarked techniques they claim enabled them to train a language model containing more than a trillion parameters.
Calling it the 'Switch Transformer', the model was around 6 times larger than GPT-3.
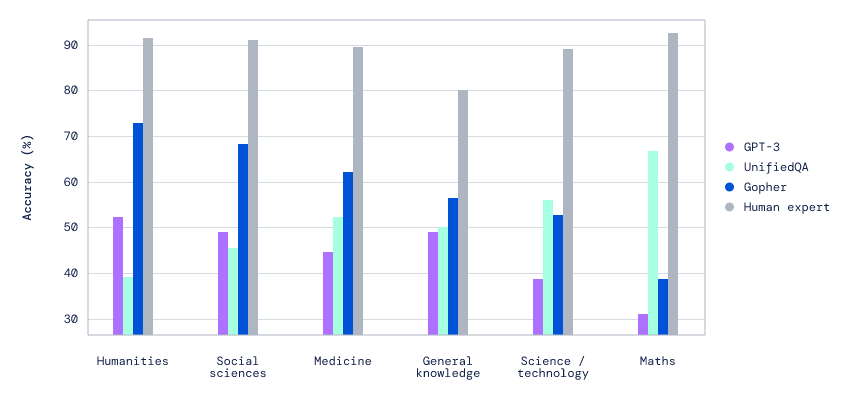
And this time, DeepMind Technologies, the British artificial intelligence that is a subsidiary of Google's parent Alphabet Inc., is also leaping forward with 'Gopher'.
This AI language model is about 60% larger, parameter-wise, than GPT-3. With 280 billion parameters, it's a little over a quarter of the size of Google’s massive trillion-parameter Switch Transformer.
Regardless, Gopher sets itself as the world's largest large language model (LLM) at the moment of its introduction.
DeepMind managed to accomplish this feat by improving the areas where expanding the size of AI is possible.
For example, DeepMind tweaked to deliver more power to the AI's reading comprehension.
By prioritizing how the system utilizes and distributes resources, the team was able to tweak their algorithms to outperform state-of-the-art models in 80% of the benchmarks used.
According to DeepMind on its blog post:
It should be noted that in the paper (PDF), it is said that Gopher using the 7B model was not compared with GPT-3 on what's called the Pile Test.
This is because the model from OpenAI was already outperformed by Jurassic-1 and by Gopher "on almost all subsets."
The researchers presented Gopher as a method for modelling arbitrary text sequences whilst retrieving from databases with trillions of tokens—scaling the data available to models by an order of magnitude compared to what is typically consumed during training.
Using the so-called Retrieval-Enhanced Transformers (Retro), which is pre-training the model with an internet-scale retrieval mechanism, the model's gains don't diminish for models with up to at least 7B parameters, and correspond to non-retrieval models with 10× more parameters on certain datasets.
Retro that is inspired by how the brain relies on dedicated memory mechanisms when learning, efficiently queries for passages of text to improve its predictions.
According to the researchers, improving language models using this method should help AIs in retrieving intensive downstream tasks such as question answering.
"Retro models are flexible and can be used without retrieval at evaluation and still achieve comparable performance to baseline models. Conversely, baseline models can be rapidly fine-tuned into Retro models to obtain nearly the same performance as if trained from scratch," the researchers concluded.
























































































































































































































































































































































































