
We all live in diversity. White and black, tall and short, rich and poor, the world we live in cannot be more complex.
With the many things we hear, see and feel, one's opinion may differ from others. This create inevitable biases that are common in the society. This apparent biases, are reflected on the data we generate. And when that data is fed to computers, they too share the same biases.
Computers are getting smarter and smarter. With the advancements in technology in general, as well as the human knowledge, we humans can do a lot of things better than we have in the past.
But biases remain, and they are plaguing machine learning.
For this reason, IBM has created a database of a million faces, compiled from a huge 100-million-image data set (Flickr Creative Commons). With machine learning technology unleashed to read as many faces as it could, the results are then isolated and cropped.
IBM hopes that with the strategy, the AI will see the real world in their own view.
Facial recognition is a technology that gains traction due to its ability of making many things more convenient. Such as unlocking our smartphones, detecting a criminal among a huge crowd, estimating someone's mood and capabilities for a job, security systems, personalization and so forth.
While we have become more or less reliant on this technology, facial recognition has too many flaws. At certain times, for example, it may fail simple tests, like calculating certain skin tones or ages.
This problem is a multi-layered one, and cannot be solved easily. Many developers of AI systems have also failed to think about this issue, making it persistent in AIs.
According to IBM's research paper introducing the million-image Diversity in Faces (DiF) data set:
The data set of a million faces is meant to be fed to the other machine learning algorithms.
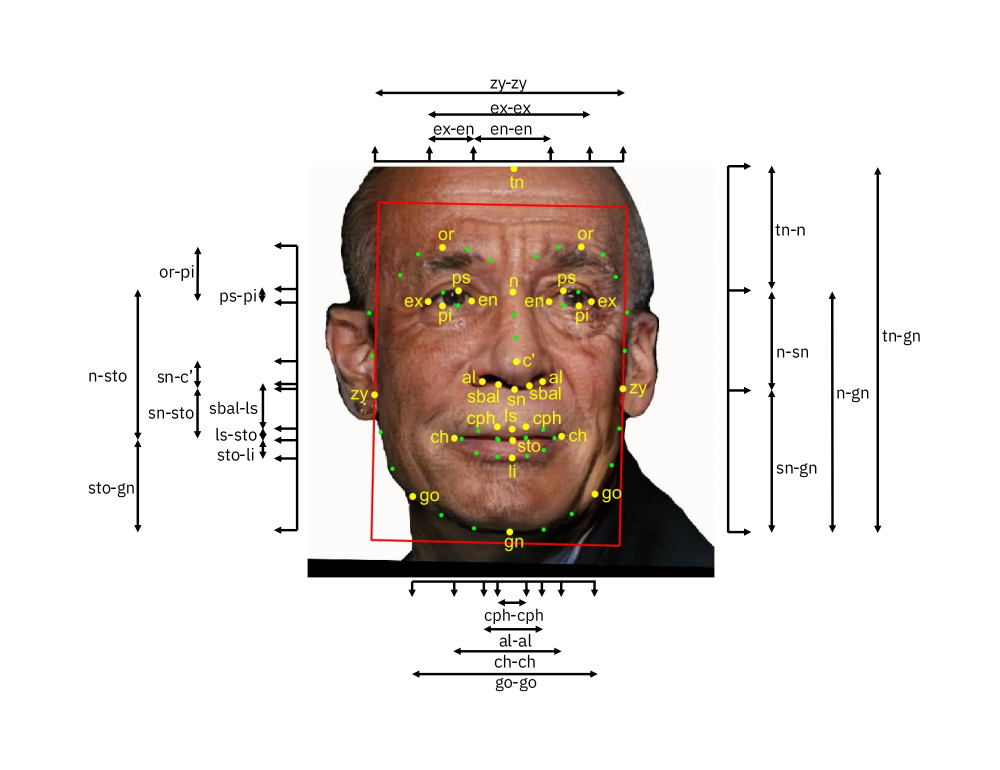
But to make sure that it understands, the researchers labeled them with metadata describing the characteristics of the subjects. For example, the team put together measurements for distance between the eyes, the size of the forehead and others.
Together, the measurements create the "faceprint" for the AI to use for matching one image to another of the same person, for example.
But since this faceprint may or may not be great in identifying people, the team revised the data set to also include things like how those measurements relate to one another.
For example, the ratio between the eyes, to the area below the nose. The team also added varieties of skin colors, as well as their contrast and coloration.
To make it even more diverse, the team also include gender. But since gender (not biological sex) is non-binary, the team represents it in any fraction between 0 and 1. This results in a metric that describes individuals in a scale from masculine to feminine.
As for age, the values are only for “reality check”.
But as for ethnicity and race, the team didn't include them as a category.
According to IBM’s John R. Smith, who led the creation of the set, ethnicity and race are often used interchangeably. Ethnicity is more related to culture while race is more related to biology. But since the differences aren't distinct, they are debatable and highly subjective.
Because including the two would introduce noise similar to what's found on previous works, the team decided to eliminate them altogether.
The research from IBM can help humans in better understand computers and how their intelligent agents' brain work. But in what is so-called the 'black box' in AI, researchers have less to no understanding about how AIs come into certain conclusion.
By mapping the data set, IBM wants to make AIs learn to see the world, in their own perspective.
It's a start, as it iis a work in progress. What this means, it doesn't promise anything. But for any work that attempts to advance AI to be less bias, that should be a welcome move.



























































































































































































































































































































































































