
Dropbox is a web-based file hosting service. Having hundreds of billions of users uploading hundreds of billions of contents, it needs a robust search engine.
Previously, Dropbox has Firefly, a search engine that was first introduced in 2015. But as Dropbox has grown much larger, becoming one the largest online storage for private documents, it needs a better search engine. And this is where the company's engineering team has been busy creating a replacement full-text search engine.
It's name is Nautilus.
As a replacement to its previous search engine, Nautilus is machine learning-powered, and should offer a more powerful search capabilities than Firefly.
Nautilus can be personalized in multiple ways: not only does each user have access to a different set of documents, but users also have different preferences and behaviors in how they search. This is in contrast to web search engines, where the focus is almost entirely on browsing behavior, but over a corpus that are largely the same for each user.
The primary objectives Dropbox has set when developing the Nautilus project were to:
- Deliver great performance, scalability, and reliability to deal with the scale of data.
- Provide a foundation for implementing intelligent document ranking and retrieval features.
- Build a flexible system that would allow its engineers to easily customize the document-indexing and query-processing pipelines for running experiments.
- Able to deliver the above objectives quickly, reliably, and with strong safeguards to preserve the privacy of users’ data.
What's unique about this search engine is that, the machine learning prioritizes ranking to retrieve a large set of matching documents, but without worrying too much about how relevant each document is to the user. What this means, Nautilus focuses only in picking the documents that the user is most likely to want right now.
To do this, the ranking engine uses AI to outputs a score for each document based on a variety of signals, including the relevance of the document to the query. Then the AI measures that relevance of the document to the user at the current moment in time.
For example, Nautilus includes things that the user has been interacting with, or what types of files the user has been working on.
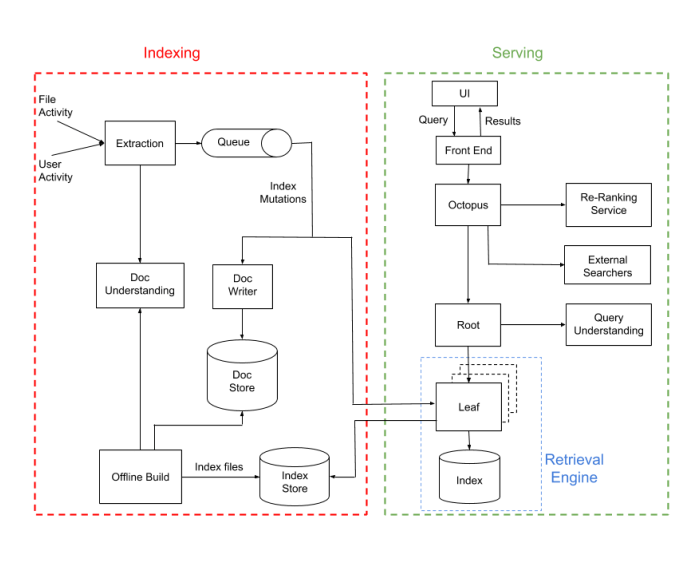
To manage this feat, Dropbox trained the model using anonymized "click" data from its front-end, which excludes any personally identifiable data.
"Given searches in the past and which results were clicked on, we can learn general patterns of relevance. In addition, the model is retrained or updated frequently, adapting and learning from general users’ behaviors over time," said Dropbox.
Dropbox uses AI-based solution for its search engine is because it uses a large number of signals, as well as to leverage automation.
"This might be doable if you only have a handful of signals, but as you add tens or hundreds or even thousands of signals, this becomes impossible to do in an optimal way. This is exactly where ML shines: it can automatically learn the right set of 'importance weights' to use for ranking documents, such that the most relevant ones are shown to the user. For example, by experimentation, we determined that freshness-related signals contribute significantly to more relevant results."
Dropbox tested Nautilus in shadow mode before making it the primary search engine. After its release, the company said that it saw "significant improvements" to the time-to-index new and updated content.