
The debate surrounding open-source AI centers on a core strategic decision for organizations, developers, and institutions: whether to build and maintain ownership over their artificial intelligence capabilities or to rely on renting them from a limited set of dominant providers.
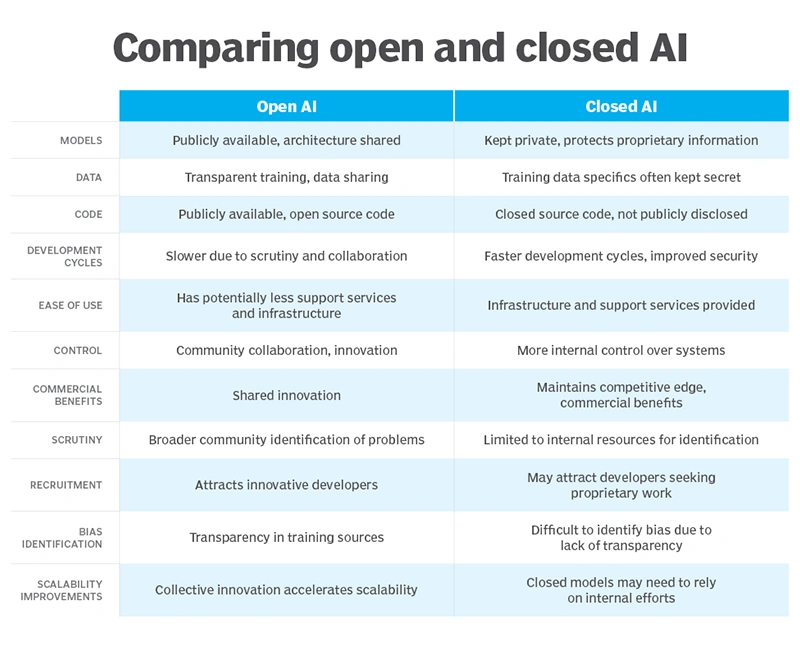
Closed models, typically offered through polished APIs and managed services, have gained widespread traction because they deliver immediate usability, reliable performance, and minimal setup requirements. Teams can integrate advanced capabilities quickly, focusing on application logic rather than underlying infrastructure or optimization challenges.
This approach suits rapid prototyping, standardized workflows, and scenarios where convenience and vendor-managed updates outweigh other priorities.
Yet renting intelligence creates inherent dependencies that extend beyond simple access.

Organizations become tied to external decisions on pricing models, rate limits, context handling, data retention policies, and even model availability or deprecation schedules.
Providers naturally prioritize their own commercial objectives, which may shift over time and introduce unexpected disruptions such as cost escalations or alterations in behavior that require rework in dependent systems. Data sovereignty concerns arise as sensitive information often flows to third-party servers, raising compliance and privacy issues in regulated industries.
In contrast, open-weight and open-source AI models empower users to host, inspect, modify, and deploy systems on their own terms, whether in private data centers, cloud environments they control, or even on-device hardware. This ownership model mirrors the broader technology landscape, where control over core assets has historically driven long-term resilience and innovation.
The parallels to earlier open-source movements in software are instructive.
Just as the dominance of proprietary operating systems and browsers gave way to collaborative alternatives that fostered competition, interoperability, and user empowerment, open AI approaches challenge concentrated control in intelligence technologies.
Early software ecosystems demonstrated how shared codebases could accelerate collective progress while preventing single-vendor lock-in. In AI, similar dynamics are unfolding: community-driven contributions enable faster iteration on architectures, training techniques, and efficiency improvements, often drawing from diverse global expertise rather than isolated corporate teams.
One of the most compelling practical advantages of open approaches lies in performance and economics.
Leading open models routinely achieve the vast majority of the capabilities demonstrated by their closed counterparts upon release, with community refinements frequently narrowing any remaining gaps within weeks or months.
Inference costs can drop dramatically, often by 70% or more, especially when models run on owned or optimized infrastructure rather than metered cloud services.
This efficiency stems from techniques like quantization, distillation, and specialized serving frameworks that allow organizations to tailor resource usage to their exact needs. Smaller, specialized models have matured to the point where capable intelligence operates effectively on consumer-grade devices, edge hardware, or resource-constrained environments, unlocking applications that demand low latency or offline functionality.
Beyond cost and performance, openness delivers deeper structural benefits.
Transparency allows developers and auditors to examine model architectures, weights, and sometimes training processes, facilitating the identification and mitigation of biases, vulnerabilities, or unintended behaviors.
This inspectability supports stronger accountability in high-stakes domains such as healthcare, finance, or public services.
Customization becomes straightforward: teams can fine-tune models on proprietary datasets, adapt them to niche languages or industry-specific terminology, or integrate them into private workflows without negotiating access restrictions.
For enterprises, this means avoiding vendor lock-in and building AI systems that evolve in lockstep with internal data and strategic goals. Governments and institutions focused on digital sovereignty gain the ability to operate models entirely within national borders or air-gapped networks, safeguarding sensitive operations from external influence.

The open ecosystem further amplifies these strengths through collaboration and shared infrastructure.
Global communities contribute improvements to foundational components, ranging from efficient inference engines and orchestration tools to standardized formats for model portability and evaluation benchmarks. Platforms that host repositories, provide serving libraries, and support distributed training lower the barriers to experimentation and scaling.
Organizations can leverage modular stacks for everything from data preprocessing to production monitoring, drawing on battle-tested open frameworks rather than starting from scratch.
This collective effort not only accelerates innovation but also distributes the burden of maintenance and security hardening across a wider pool of contributors, often resulting in more robust long-term outcomes than isolated proprietary development.
Open AI also aligns particularly well with emerging deployment patterns such as edge computing.
In scenarios requiring real-time decision-making. autonomous systems, industrial monitoring, smart infrastructure, or remote healthcare, processing data locally reduces latency, bandwidth costs, and exposure of raw inputs.
Models can run inference directly on sensors, gateways, or local servers, preserving privacy and enabling operation in environments with intermittent connectivity.
Enterprises in manufacturing, logistics, or energy sectors benefit from predictive maintenance, quality control, or optimization loops that operate independently of cloud round-trips. For public-sector applications, edge-enabled open models support everything from traffic management in smart cities to secure, localized analysis of citizen services without relying on foreign-hosted providers.

Despite these advantages, adopting open-source AI demands a clear-eyed assessment of its requirements and trade-offs.
Implementation typically involves greater upfront investment in technical expertise, hardware or cloud resources, and integration efforts. Teams must handle model serving optimization, security patching, performance monitoring, and lifecycle management tasks that closed services often abstract away.
Documentation quality and tooling maturity can vary across projects, requiring organizations to invest in internal capabilities or partner with experienced providers. Security considerations include the need for rigorous vetting of downloaded components to guard against supply-chain risks, adversarial attacks, or data-poisoning attempts that may surface more readily in publicly accessible repositories.
Quality control relies on community scrutiny rather than centralized testing, which can lead to inconsistencies in reliability or hallucination rates until additional validation layers are applied.
Licensing and compliance add another layer of complexity.
Not all releases labeled "open" provide identical levels of access, some offer weights alone while others include full training code or datasets, and terms can range from permissive to more restrictive commercial-use clauses.
Enterprises operating in regulated sectors must evaluate alignment with data-protection laws, audit requirements, and ethical guidelines, sometimes necessitating supplementary governance frameworks. Smaller teams or those prioritizing speed-to-market may still find closed platforms more pragmatic for initial exploration, where polished interfaces and dedicated support reduce operational overhead.

The maturing open-source AI landscape continues to address many of these hurdles through improved developer experiences.
Advances in user-friendly interfaces, automated deployment pipelines, comprehensive monitoring suites, and pre-optimized model variants are steadily narrowing the usability gap.
As inference hardware becomes more accessible and best practices for secure, scalable operations disseminate more widely, self-hosted or customized AI grows increasingly viable as a default rather than a niche choice. This evolution supports a hybrid reality in which open and closed models coexist: organizations select the right tool for each context, combining the rapid innovation and cost efficiency of openness with the polished reliability of proprietary services where appropriate.
Ultimately, the trajectory of AI development hinges less on raw benchmark scores alone and more on questions of control, adaptability, and equitable access.
Decision-makers across industries face an ongoing evaluation: the trade-offs of dependency on rented intelligence versus the responsibilities and rewards of ownership.
By fostering transparency, collaboration, and sovereignty, open approaches hold the potential to democratize powerful capabilities while mitigating the risks of concentrated power.
As supporting tools and practices advance, the choice between owning and renting intelligence becomes not merely technical but foundational to long-term strategic autonomy, innovation velocity, and resilience in an AI-driven future. Organizations that thoughtfully invest in the open ecosystem position themselves to shape and benefit from the next wave of technological progress on their own terms.