

People search for practically anything on the web. And search engines that are expected to show them the answers, usually receive queries they've never seen.
Bing is Microsoft's search engine. While it's far less popular that Google, it has indeed provided many unique features. But when dealing with users' intent, things can be difficult.
This is why, said Microsoft, the search engine started using 'Bidirectional Encoder Representations from Transformers'. Or better known as 'BERT', this natural-language understanding uses transformers to understand the context and relationship between each word and all the words around it.
This is a contrast to the previous deep neural network architecture which processed words individually in order.
According to Microsoft's blog post, the company said that:
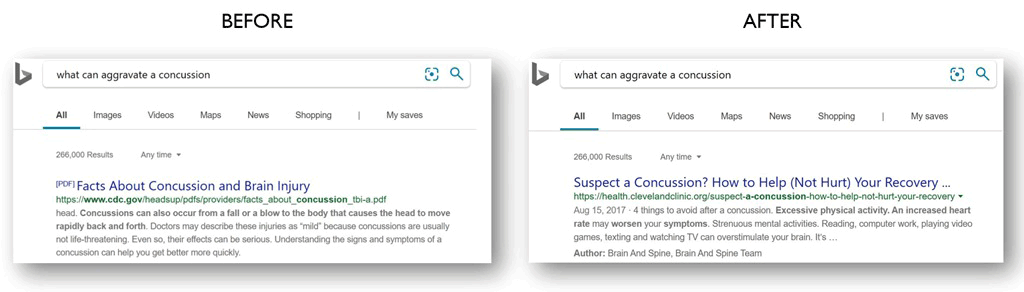
When using search engines, users expect fast answers to their queries. Here, every millisecond of latency matters.
To achieve great search speed, the transformer-based models are pre-trained with up to billions of parameters, which is a sizable increase in parameter size and computation requirement as compared to previous network architectures.
One of the major differences between transformers and previous deep neural network architectures is that it relies on massive parallel compute instead of sequential processing. Here, Bing utilizes Microsoft Azure’s N-series Virtual Machines (VM) with GPU accelerators to accelerate the transformer models.
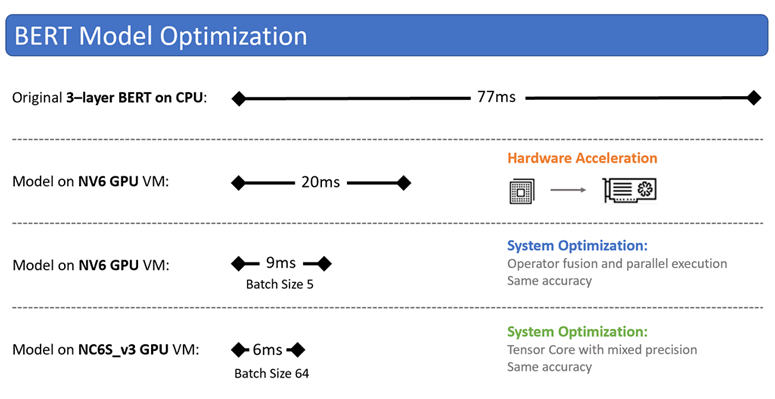
Initially, Bing used the NV6 VM due to lower cost and regional availability. Using three-layer BERT on that VM with GPU, the search engine experienced a serving latency of 20ms. This is about three times faster than when using deep neural network architecture.
To further improve the serving efficiency, Microsoft partnered with NVIDIA to take full advantage of the GPU architecture and re-implemented the entire model using TensorRT C++ APIs and CUDA or CUBLAS libraries, including rewriting the embedding, transformer, and output layers.
After optimizations, the same Azure NV6 VM was able to serve a batch of five inferences in 9ms, or 8 times latency speedup and 43 times throughput improvement compared to the model without GPU acceleration.
And when leveraging Tensor Cores with mixed precision on a NC6s_v3 VM, Bing was able to an ~800x throughput improvement compared to CPU.
Bottom Line
Users expect fast experience, no matter what.
As a search engine competing with Google, Bing wants to better understand natural language users use as queries. Using BERT, the transformer models should lead users to more relevant answers with faster search experiences.
In Bing, BERT builds on the deep learning capabilities previously used in Bing’s Intelligent Search features, such as Intelligent Answers, Intelligent Image Search with object recognition, and hover-over definitions for uncommon words.
Competitor Google also uses BERT to advance its algorithms. So with Bing's update, this makes two search engines using BERT for better natural language processing. However, Bing’s implementation of BERT to improve its search results pre-dates Google’s BERT announcement by six months.
What's more, with Bing utilizing BERT worldwide to every query, Bing is utilizing BERT at a much larger scale than Google. This is because Google only uses BERT for a mere 10% of search results in the U.S., as of Bing's announcement of BERT.
What this means, the improvements, and a bit of head start, should help Bing preserve and grow its share of the search market.