
The rise of Large Language Models (LLMs) and generative AI has made these technologies more prevalent than ever.
However, staying competitive in this rapidly evolving landscape requires continuous improvement. Since OpenAI introduced ChatGPT, companies have been striving to enhance their AI models, often relying on user data for training.
This practice raises significant privacy concerns, as many users are wary of their information being used to refine AI systems—potentially turning their input into anonymous contributions to a broader public knowledge base.
Bluesky, a decentralized social media platform and a direct competitor to X (formerly Twitter), has also announced plans to use user data for AI training.
However, unlike other platforms, Bluesky will allow users to control how their data is utilized, offering the option to customize data-sharing preferences or opt out entirely.
Read: How 'Bluesky' Finally Became The Old-School Twitter That X Could Never Be
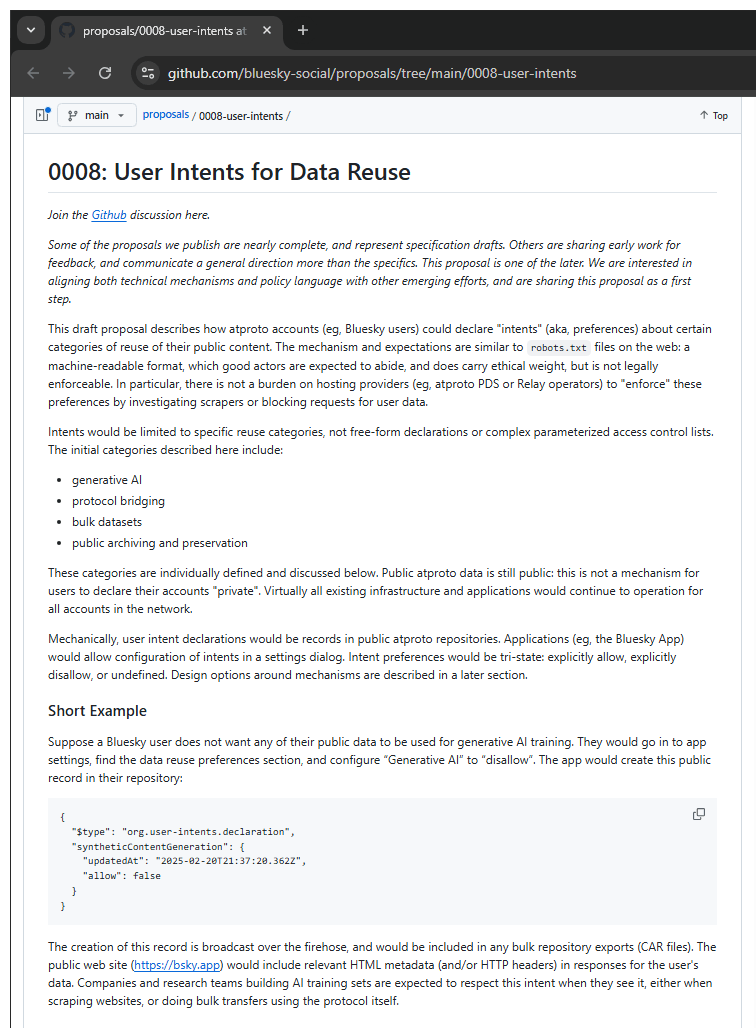
During the SXSW conference in Austin, Bluesky CEO Jay Graber has stated that Bluesky is developing a framework that will empower users with control over their data. This will allow individuals to decide how much—if any—of their content can be used for AI training, giving them the option to opt out entirely.
"We really believe in user choice," Graber said, saying that users would be able to specify how they want their Bluesky content to be used.
"It could be something similar to how websites specify whether they want to be scraped by search engines or not," she continued.
"Search engines can still scrape websites, whether or not you have this, because websites are open on the public Internet. But in general, this robots.txt file gets respected by a lot of search engines," she said. "So you need something to be widely adopted and to have users and companies and regulators to go with this framework. But I think it’s something that could work here."
The proposal, which is available on GitHub, would involve getting user consent at the account level or even at the post level, then ask other companies to respect that setting.
"We’ve been working on it with other people in the space concerned about how AI is affecting how we view our data," Graber added.
"I think it’s a positive direction to take."
The demand for AI training data is evident, and Bluesky, despite its young age, has to think far ahead.
In this case, it needs to think about its AI policy, even though it doesn’t plan to train its own AI systems on users’ posts.
It's worth noting that the public nature of Bluesky’s social network has already enabled third parties to train AI models using user-generated content. This became evident when a dataset containing 1 million Bluesky posts was discovered on Hugging Face, a popular platform for hosting AI models and datasets.
While Bluesky itself has not directly facilitated this, the decentralized and open-source nature of the platform means that user posts are publicly accessible, making them susceptible to scraping by external AI developers.
This revelation further highlights the ongoing privacy concerns surrounding AI training and the need for stronger user controls over data usage.
This marks a significant shift in strategy.
Back in 2024, when many users abandoned X over concerns about their data being used for AI training, Bluesky reassured its community that their information would be safeguarded from such practices.
While the company has technically upheld its promise, it cannot prevent third-party AI firms from scraping and utilizing publicly available content. The open-source nature of the decentralized platform means that all posts exist within a public feed, accessible to anyone.


























































































































































































































































































































































































