

Artificial Intelligence (AI) systems are only as good as the data they have been given. And one huge dataset has been taken down.
The dataset is called '80 Million Tiny Images'. Created by the people at the Massachusetts Institute of Technology (MIT), it compiled a large number of labeled images scraped from Google Images.
Containing enough data for computer-vision algorithms in the late-2000s and early-2010s to digest, it also has a high number of images with labels that can deceive computers into understanding what they shouldn't believe.
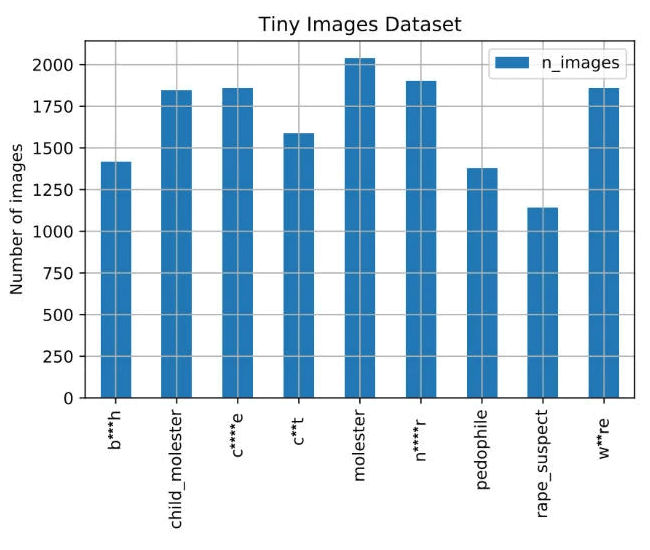
Discovered by Vinay Prabhu, chief scientist at privacy startup UnifyID, and Abeba Birhane, a PhD candidate at University College Dublin in Ireland, the library was found to have labeled women as whores or bitches, and Black and Asian people with derogatory language.
The database also contained close-up pictures of female genitalia labeled with the C-word.
The database was removed after The Register alerted the American private research university.
MIT wrote a letter to apologize on a dedicated web page, saying that:
The dataset is too large (80 million images) and the images are so small (32 x 32 pixels) that it can be difficult for people to visually recognize its content. Therefore, manual inspection, even if feasible, will not guarantee that offensive images can be completely removed.
We therefore have decided to formally withdraw the dataset. It has been taken offline and it will not be put back online. We ask the community to refrain from using it in future and also delete any existing copies of the dataset that may have been downloaded.
Created in 2008, the dataset was originally meant to help create advanced object detection methods, and has then been used to teach machine-learning models to identify people and still objects.
It is essentially a huge collection of photos with labels describing what's in the them.
With the huge amount of labeled data, developers and neural network researchers can teach their AI models with the examples, in order for their models to associate the patterns inside the photos, to then understand what they will see in the future.
For example, when shown a photo of a park, an AI trained with the dataset should be able to extract information, such as children, adults, pets, picnic spreads, grass, and trees present in the photo.
However, since the dataset contained misleading images and labels, AI systems trained with the dataset can potentially describe people using racist, misogynistic, and other problematic terms.
This damage of such ethically dubious datasets can go beyond bad taste.
Any AI model on applications, websites, and other products relying on neural networks trained using the dataset can end up using those terms when analyzing photographs and camera footage.
This in turn can create sexist or racist chatbots, racially-biased software, and others that could be worse.
After putting the dataset offline, MIT also urged researchers and developers who are using the training library to to stop using it and to delete any copies.
Having been created more than a decade ago, the Tiny Images dataset was in fact outdated in the modern days' terms. This is why the dataset is more popular for benchmarking computer-vision algorithms along with the better-known ImageNet training collection.
Vinay Prabhu and Abeba Birhane have revealed their findings in a paper titled Large image datasets: A pyrrhic win for computer vision?.