

Reinforcement learning (RL) is one of three basics of machine learning paradigms, alongside supervised learning and unsupervised learning.
As a way for machine learning agents to train, RL enforces them to take actions in an environment in order to maximize the notion of cumulative reward. The method focuses on optimizing the agents for specific goals, by finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).
RL has shown success in solving the strategy board game Go and the multiplayer online battle arena video game Dota 2, for example.
However, RL techniques require increasingly large amounts of training to successfully learn even simple games.
This makes the process of training computationally expensive and time consuming.
In a published paper, Google researchers describe a framework called 'SEED RL' that scales AI model training to thousands of machines.
As explained by the researchers in a Google blog post:
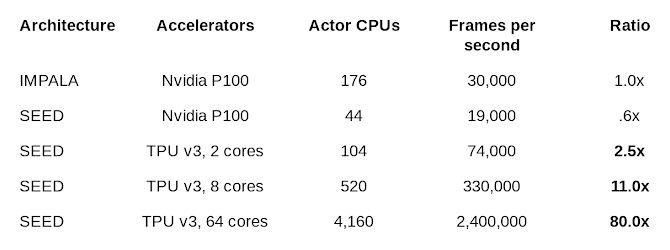
Here, the researchers said that SEED RL could facilitate training at millions of frames per second on a machine while reducing costs by up to 80%, potentially opening the AI field for more startups that couldn't previously compete with huge AI labs.
SEED RL is based on Google’s TensorFlow 2.0 framework, which features an architecture that takes advantage of graphics cards and tensor processing units (TPUs) by centralizing model inference.
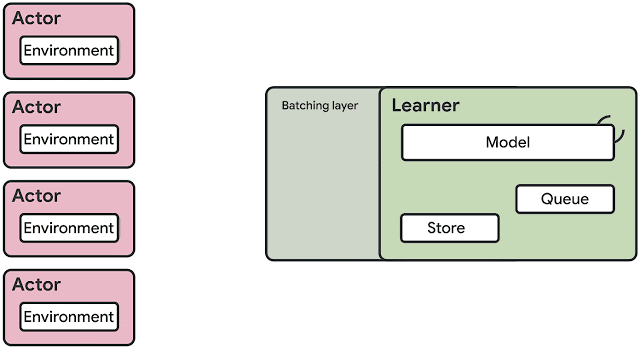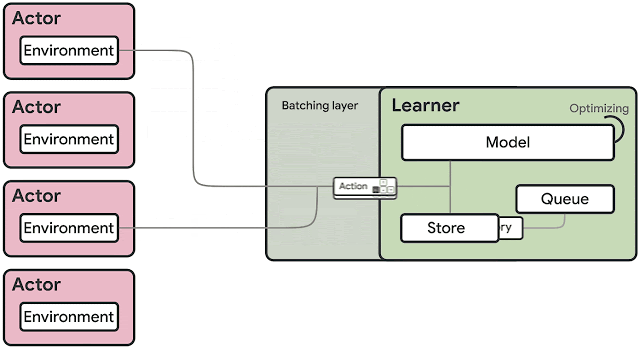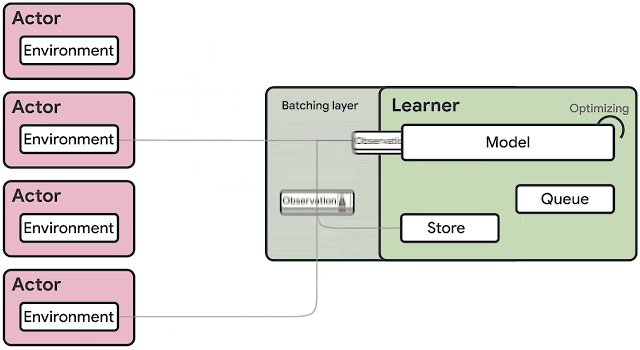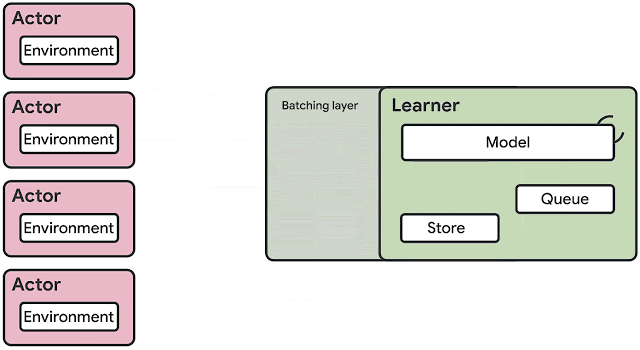
To avoid data transfer bottlenecks, SEED RL performs AI inference centrally with a learner component that trains the model using input from distributed inference.
The target model’s variables and state information are kept local, while observations are sent to the learner at every environment step and latency is kept to a minimum thanks to a network library based on the open source universal RPC framework.
According to Google, SEED RL’s learner component can be scaled across thousands of cores, and the number of actors.
To evaluate SEED RL, the researchers benchmarked it on the commonly used Arcade Learning Environment, several DeepMind Lab environments, and the Google Research Football environment.
And this is where they got the numbers.
The researchers said that they managed to solve a previously unsolved Google Research Football task using 2.4 million frames per second with 64 Cloud TPU cores, which is an improvement over the previous state-of-the-art distributed agent by 80 times.
“This results in a significant speed-up in wall-clock time and, because accelerators are orders of magnitude cheaper per operation than CPUs, the cost of experiments is reduced drastically,” wrote the coauthors of the paper.
“We believe SEED RL, and the results presented, demonstrate that reinforcement learning has once again caught up with the rest of the deep learning field in terms of taking advantage of accelerators.”