

One sentence can mean different things. And when it comes to understanding that context, language-based AI models often struggle.
To solve this problem, Google has introduced a model it calls 'Reformer'. What it does, is to understand the context of sentences and paragraphs using far less memory. This is a huge step up if compared to the resource hungry model 'Transformer', which is a neural network that compares words in a paragraph to each other to understand the relationship between them.
The main disadvantage of Transformer is its way of understanding context using pair matching.
For example, to understand just a few lines or paragraphs, Transformer needs a lot of space to work because it compares all words with each other at the same time.
This makes it impractical when a language-processing AI needs to process a long article or a book.
Reformer on the other hand, uses locally-sensitive-hashing (LSH). This method is meant to solve the problem of a short ‘attention span’ and memory consumption of Transformer, by using hash function to group similar words together, to then compare the words with each other in the same or neighboring group.
This should significantly reduce processing overload.
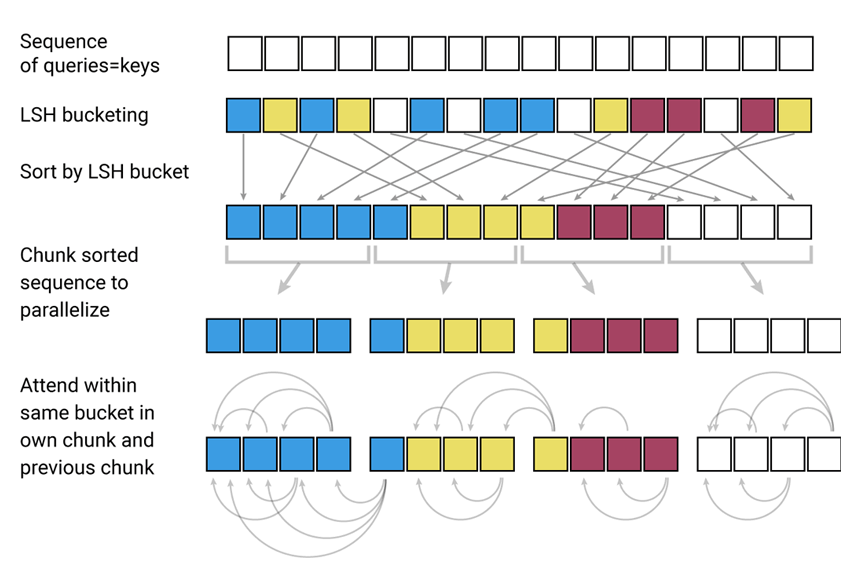
According to Google researchers in a blog post:
However, extending Transformer to even larger context windows runs into limitations. The power of Transformer comes from attention, the process by which it considers all possible pairs of words within the context window to understand the connections between them"
LSH can also solve memory problem that can happen when using the old model.
To do this, the second novel approach implemented in Reformer is to recompute the input of each layer on-demand during back-propagation, rather than storing it in memory. This is done by using reversible layers, where activations from the last layer of the network are used to recover activations from any intermediate layer, by what amounts to running the network in reverse.

Using the two approaches, Reformer can be highly efficient.
According to the researchers, Reformer can process text sequences of lengths up to 1 million words on a single accelerator using only 16GB of memory.
Because of this, Reformer can be applied directly to data with context windows much larger than virtually all current state-of-the-art text domain datasets.
To test this model, Google fed Reformer some images. Here, the researchers presented examples of how Reformer can be used to “complete” partial images. Starting with the image fragments shown in the top row, Reformer can generate full frame images, pixel-by-pixel.
The researchers also suggested that because Reformer uses a lot less memory, it should be able to read entire novel, all at once, on a single device. This is a process previously daunting for AIs.
"We believe Reformer gives the basis for future use of Transformer models, both for long text and applications outside of natural language processing," the researchers said.