

Dementia is a general term for a decline in cognitive function severe enough to interfere with daily life.
While dementia it's not a specific disease, dementia is more like a syndrome associated with various underlying conditions that affect memory, thinking, behavior, and the ability to perform everyday activities. Causes vary from the presence of amyloid plaques and tau tangles in the brain, to reduced blood flow to the brain, abnormal protein deposits, degeneration of the frontal and temporal lobes, or a combination of them.
In all, dementia is associated to living things that made up of cells and tissues.
Not computers that are made of silicon and some metals and ceramics.
And researchers have found how they correlate.
AI products learn from the datasets they have been given, churning the information to find patterns in them.
In all, the methods include supervised learning, unsupervised learning, semi-supervised learning, reinforcement learning, and deep learning.
Along the way, the AI can pick up information it shouldn't.
This can happen there is no way to really filter out bad information, considering that AI can only learn to become better by churning more and more information, on the scale that include the whole internet.
Researchers sought to create "unlearning" techniques, meant to make generative AI models forget specific and undesirable information it learned from its training data.
In the event that followed the rise of generative AI, which came after OpenAI's introduction of ChatGPT, an increasing number of copyright holders and privacy-concerned individuals are against having tech companies learning from their data.
But here, researchers found that making AI unlearn what it learned, could make models like OpenAI’s GPT-4o or Meta’s Llama 3.1 405B much less capable of answering basic questions.
That’s according to a study co-authored by researchers at the University of Washington (UW), Princeton, the University of Chicago, USC and Google.
They found that the most popular unlearning techniques tend to degrade models, often to the point where they're unusable.
According to Weijia Shi, a researcher on the study and a Ph.D. candidate in computer science at UW, to TechCrunch:
"Currently, there are no efficient methods that enable a model to forget specific data without considerable loss of utility."
The issue stems from the fact that generative AI models do not have real intelligence. Instead, they're just statistical systems that predict words, images, speech, music, videos and other data.
After being fed an enormous number of examples in the form of data, these models learn how likely data is to occur based on patterns, including the context of any surrounding data.
Unlearning could also provide a way to remove sensitive info from existing models, like medical records or compromising photos, in response to a request or government order. But here, unlearning what they've leaned isn't as easy as hitting the 'delete' button.
This is because the available unlearning methods rely on algorithms designed to make AI models to "steer" away from the data they need to forget.
The idea is to influence the model to stop outputting certain data.
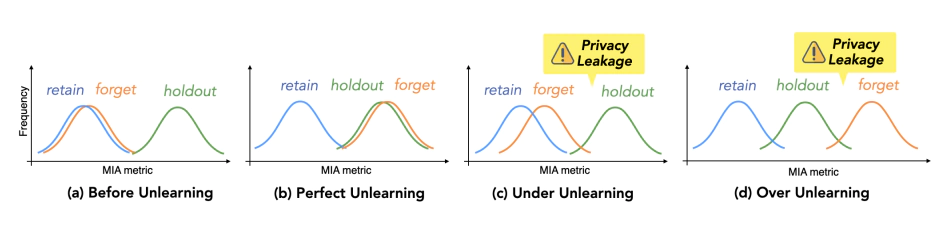
But what happens here is that, the researchers found that the unlearning algorithms they tested did make models forget certain information, but also make their performance to deteriorate.
Shi went on to explain that:
"For instance, a model may be trained on copyrighted material — Harry Potter books as well as on freely available content from the Harry Potter Wiki. When existing unlearning methods attempt to remove the copyrighted Harry Potter books, they significantly impact the model’s knowledge about the Harry Potter Wiki, too."
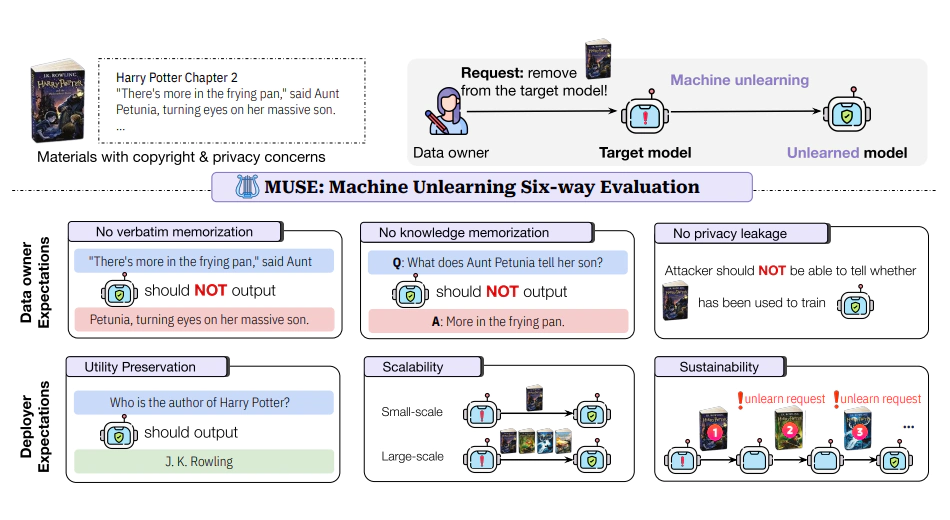
The researchers use a method called MUSE (Machine Unlearning Six-way Evaluation).
The benchmark aims to probe an algorithm’s ability to not only prevent a model from spitting out training data verbatim (a phenomenon known as regurgitation), but eliminate the model’s knowledge of that data along with any evidence that it was originally trained on the data. The approach is to see the effectiveness of available unlearning algorithms.
At this time, there is no solution to this problem.
What the researchers know, once an AI model learned something, it would be next to impossible for it to unlearn what it learned, without giving it a slight dementia.