As the largest search engine around on the web and beyond, Google is dealing with a lot of text contents and unimaginable number of user queries.
No humans can cope the number that Google is relying heavily on automation and AI. That in order to lift most of the heavy burdens of computing, and allow Google Search to learn as it goes, based on the algorithms to govern what it does.
But things shouldn't stop there, as the more content it has to deal with, the ratio of toxicity increases, and the factuality decreases.
This happens because the more data it has to churn, it's inevitable that it has to process more toxic content.
Among the ways Google is trying to improve its search engine, the company announced 'KELM', which is a way that could be used to reduce biases and unwanted content in search.
To do this, KELM uses a method called TEKGEN (Text from KG Generator) to convert Google's Knowledge Graph facts into natural language text that can then be used to improve natural language processing models.
In other words, Google is using its own answers to further fine-tune its AI, to then use that AI to provide better answers.
In a blog post at Google AI, the company wrote that:
"Alternate sources of information are knowledge graphs (KGs), which consist of structured data. KGs are factual in nature because the information is usually extracted from more trusted sources, and post-processing filters and human editors ensure inappropriate and incorrect content are removed. Therefore, models that can incorporate them carry the advantages of improved factual accuracy and reduced toxicity. However, their different structural format makes it difficult to integrate them with the existing pre-training corpora in language models."
KELM is an acronym for 'Knowledge-Enhanced Language Model Pre-training'.
With it Google aims to "explore converting KGs to synthetic natural language sentences to augment existing pre-training corpora, enabling their integration into the pre-training of language models without architectural changes."
Google sees this as a chance of improving its existing system, simply because KELM's propose is to add trustworthy factual content (knowledge-enhanced) to the language model pre-training, in order to improve the factual accuracy and reduce bias.
Researchers at Google proposed using Knowledge Graphs for improving factual accuracy because they’re already a trusted source of facts.
“Alternate sources of information are knowledge graphs (KGs), which consist of structured data. KGs are factual in nature because the information is usually extracted from more trusted sources, and post-processing filters and human editors ensure inappropriate and incorrect content are removed.”

To work with this KELM, Google leverages the the publicly available English Wikidata Knowledge Graph the search engine uses, and then convert it into natural language text in order to create a synthetic corpus.
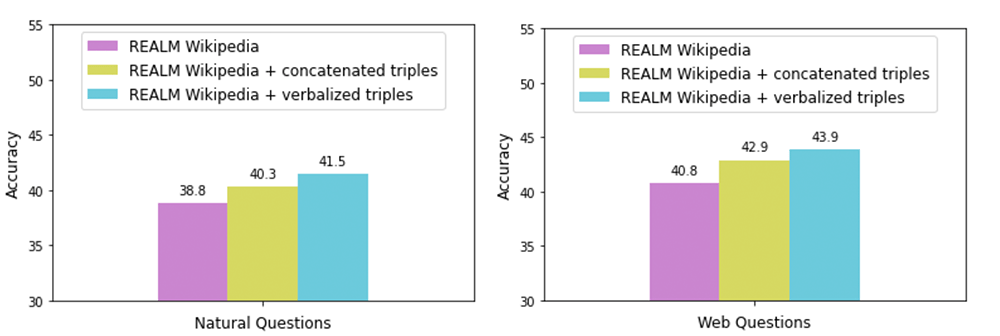
"We then augment REALM, a retrieval-based language model, with the synthetic corpus as a method of integrating natural language corpora and KGs in pre-training. We have released this corpus publicly for the broader research community," Google explained.
Knowledge Graphs not only consist of factual information, as they are represented in a structured format. Information is already grouped in related "triples" that are called "entity subgraphs".
Google converts these subgraphs into natural language text, in a standard task in NLP known as data-to-text generation.
"Although there have been significant advances on data-to-text-generation on benchmark datasets such as WebNLG, converting an entire KG into natural text has additional challenges," Google explained.
"The entities and relations in large KGs are more vast and diverse than small benchmark datasets. Moreover, benchmark datasets consist of predefined subgraphs that can form fluent meaningful sentences. With an entire KG, such a segmentation into entity subgraphs needs to be created as well."
To create the segmentation, this is where TEKGEN is used.
TEKGEN is made up of the following components: a large training corpus of heuristically aligned Wikipedia text and Wikidata KG triples, a text-to-text generator (T5) to convert the KG triples to text, an entity subgraph creator for generating groups of triples to be verbalized together, and finally, a post-processing filter to remove low quality outputs.
The result is a corpus containing the entire Wikidata KG as natural text, which Google refers to as the Knowledge-Enhanced Language Model (KELM) corpus.
According to Google, its research shows that Knowledge Graph verbalization is an effective method of integrating Knowledge Graph's natural language text.
"With KELM, we provide a publicly-available corpus of a KG as natural text. We show that KG verbalization can be used to integrate KGs with natural text corpora to overcome their structural differences."
The method has real-world applications for knowledge-intensive tasks, such as question answering, where providing factual knowledge is essential, Gogle said.