

The AI boom may have introduced a lot of advances in technology and information retrieval. But not everyone likes it.
Just like what had happened before this, a lot of the internet's most influential players have decided to block Apple from scraping their content for AI training. In this case, they include Facebook, Instagram, Craigslist, Tumblr, The New York Times, The Financial Times, The Atlantic, Vox Media, and more.
To do this, they have blocked Applebot-Extended, the Apple specialized bot, from scraping content from their websites.
They have all done this in less than three months after Apple quietly debuted a tool for publishers to opt out of its AI training.
This has once again signaled a brewing conflict over intellectual property in the digital age.
Read: 'Apple Intelligence' Brings Generative AI Into Apple, With OpenAI ChatGPT's Help
The cold response to the bot's presence highlights a major shift in how web crawlers are perceived and used.
First of, Applebot-Extended is an extension to Apple’s web-crawling bot that specifically lets website owners tell Apple not to use their data for AI training.
The original Applebot, announced in 2015, initially crawled the internet to power Apple’s search products like Siri and Spotlight.
But with the rise of AI in the tech sphere, Apple has expanded the purpose of Applebot, to also be able to collect data for AI training purposes.
Because Apple cannot simply scrape the internet without permission and not face any legal troubles, Applebot-Extended is made as a way to respect publishers' rights, as explained by Apple spokesperson Nadine Haija.
By allowing websites to opt out, the move doesn’t actually stop the original Applebot from crawling the website, but instead prevents that data from being used to train Apple's large language models and other generative AI projects.
In Apple's words explaining how it works, the company calls this "controlling data usage."
In other words, Applebot-Extended, in essence, is just a bot to customize how another bot works.
"Applebot-Extended does not crawl webpages," said Apple in a dedicated support page.
"With Applebot-Extended, web publishers can choose to opt out of their website content being used to train Apple’s foundation models powering generative AI features across Apple products, including Apple Intelligence, Services, and Developer Tools."
Giving websites the ability to opt out, many chose to opt out, rather than Apple use their content as if they're theirs for the taking.
Second, the move by the many major publishers and websites, marks how the public has changed its perception towards bots.
Once, bots were simply tools for indexing the web.
But with generative AI and the trends of people using Large Language Models to fetch information faster than ever, bots are now at the heart of a heated conflict.
As they become crucial for collecting AI training data, they’ve ignited debates over intellectual property and the future direction of the internet. This evolution reflects a growing tension around the role of automated data collection in shaping the digital landscape.
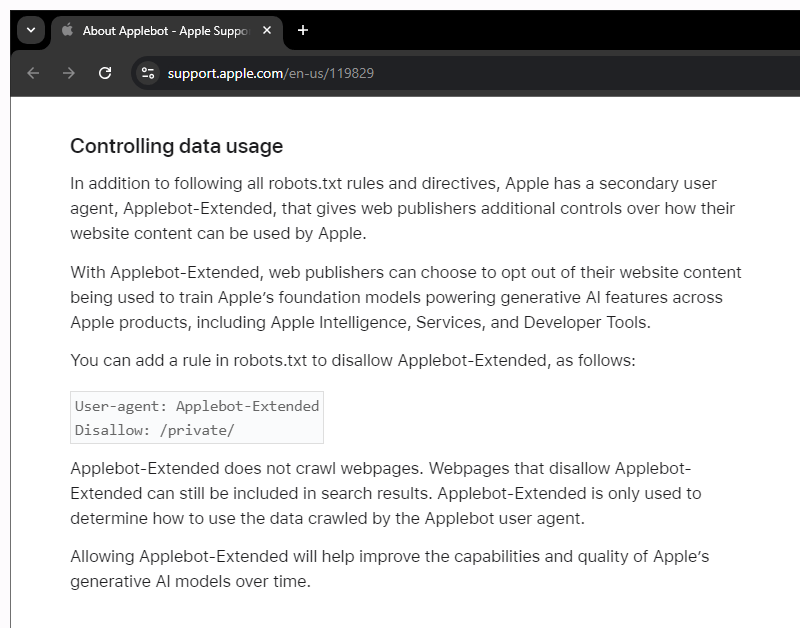
Websites that wish to block Applebot-Extended can update their robots.txt file on their websites.
The text file, known as the Robots Exclusion Protocol, has long governed how "good" bots go about scraping the web for decades.
Initially, around 6% to 7% of high-traffic websites have blocked Applebot-Extended, with news and media outlets leading the charge.
At this time, the tool is only months old, and that many websites may not have addressed its use yet.
It's worth noting that Apple has been offering publishers millions of dollars for the right to scrape their websites, as opposed to Google which believes all data should be freely available to train AI large language modules.
What this literally means, Applebot-Extended is how Apple honors a system where a website can just say in a particular file that it does not want to be scraped.