

It's an arms race. Like it or not, a war is happening on the web.
But not just any war. It's discrete, and full of secrecy. It involves strategies to circumvent rules and disobey directives. It's a war to devour the internet, and get as much as possible, as fast as possible. Go in, and out, trying to be fully undetected.
Since OpenAI introduced ChatGPT and created a competition where tech companies race to create powerful generative AIs, they soon realize that the limitation of their products: data.
With limited training materials, their AI products that hunger for data, needs to be fed to become smarter.
Companies have resorted to synthetic data, and also pay for websites to provide their data.
But because publicly-available data is "free data", why not just take them all?
Meta is doing that, using a crawler it calls the 'Meta-ExternalAgent'.
Meta, the parent company of Facebook, Instagram, and WhatsApp, has updated a section of its web page for developers, to announce the existence of the new Meta-ExternalAgent crawler in late July.
The thing is, the company never disclosed this publicly.
And as it was found, it's realized that the crawler is an automated bot that copies, or "scrapes," all the data that is publicly displayed on websites.
Meta-ExternalAgent is essentially a web scraper that scrapes pretty much everything that is visible to the public.
From news articles to blog posts, to conversations in online discussion groups, to Q&A websites, forums, bulletin boards, and even comment boxes.
Whatever things that are visible to the public, is there for the crawler to scrape.
As for what purpose, it's realized that Meta has quietly unleashed this particular web crawler to scour the internet and collect data en masse to feed its AI model.
Earlier this 2024, Mark Zuckerberg, Meta's co-founder and longtime CEO, boasted on an earnings call that Meta had amassed a data set for AI training that was even "greater than the Common Crawl," an entity that has scraped roughly 3 billion web pages each month since 2011.
The existence of Meta-ExternalAgent as a new crawler suggests that Meta's vast trove of data may no longer be enough to train its AI.
As the company continues to work on updating LLaMA and expanding its Meta AI intitiative, the company needs all the data it needs.
And the internet is undoubtedly the largest source of "free" information.
Read: Google Said It Has The Right To 'Collect' Public Information From The Web To Train Its Bard AI
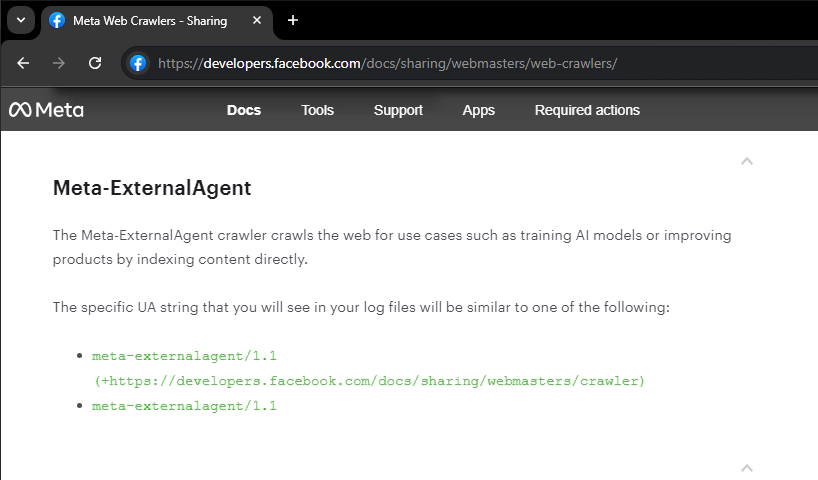
A Meta spokesman said that the company has had a crawler under a different name "for years."
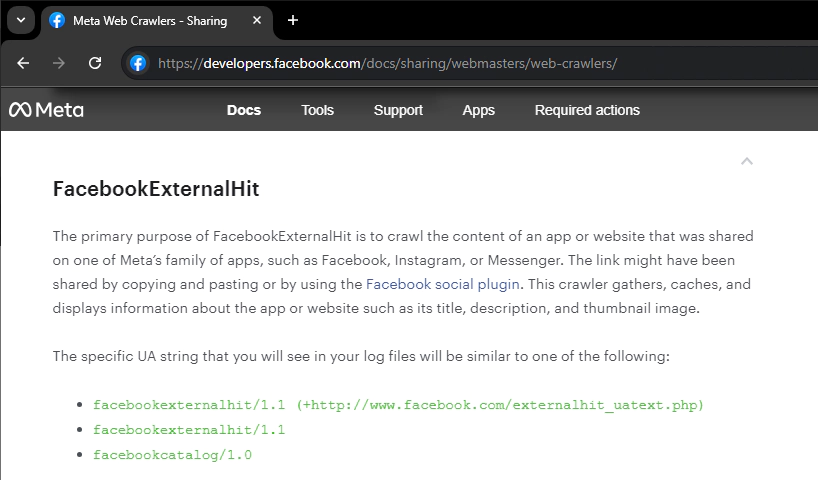
But it was called 'Facebook External Hit', and that it "has been used for different purposes over time, like sharing link previews."
"Like other companies, we train our generative AI models on content that is publicly available online,” the spokesman said. “We recently updated our guidance regarding the best way for publishers to exclude their domains from being crawled by Meta’s AI-related crawlers."
But this Meta-ExternalAgent is different.
Whereas Facebook External Hit's primary purpose is to "crawl the content of an app or website that was shared on one of Meta’s family of apps, such as Facebook, Instagram, or Messenger," the Meta-ExternalAgent crawler "crawls the web for use cases such as training AI models or improving products by indexing content directly."
So here, the two bots are two different entities, made for a different purpose.
And there is probably no way to totally stop them.
Read: OpenAI Upgrades GPT-3, And Announces What It Calls The 'ChatGPT' AI
Meta said that website owners can configure their site's robots.txt file to specify to the Meta web crawlers how they would prefer them to interact with their site, and that they can block the crawlers by adding a disallow directive for the relevant crawler.
However, Meta also said that some of its crawlers "may bypass" the robots.txt, like when performing security or integrity checks.
What this means, while website owners can use directives to allow or disallow certain bots from ever crawling or indexing the content of their site.
Typically whatever command is written in the robots.txt is respected. But in this case, operators of scraper bots can also simply choose to ignore the directives altogether.
They can do this, however they want.
The directives provided in the robots.txt are not enforceable or legally binding in any way.
Scraping web data to train AI models is a controversial practice that has led to numerous lawsuits by artists, writers, and others.
Many of them have all said that AI companies used their content and intellectual property without their consent.
It's worth noting that OpenAI has a bot that does something similar to this. It's called the GPTBot, and just like Meta's crawler, the bot also wants to "consume the entire internet".