

Google and privacy may not be the best of friends. With an army of trackers, Google is definitely at the top of the 'online snooping' food chain.
And for that particular reason, many aren't happy with Google. From privacy advocates, governments and regulators around the world, they have demanded the company to provide more transparency about its data gathering practices.
Even for a company that admits that it gather user data for ad targeting purposes, having external parties to continuously probe into how it conduct business isn't a great experience.
This is why Google has been defending itself, saying that it isn't collecting user data without user consent.
And this time, the company is proving that it's dead serious about preserving privacy, by open-sourcing a library it uses to glean insight from aggregated data.
Called 'Differentially Private SQL', the library leverages the idea of differential privacy (DP), which is a statistical technique that makes it possible to collect and share aggregate information about users, while safeguarding individual privacy.
Available on GitHub, this library allows developers and organizations to build tools that can learn from aggregated user data, without having to reveal any personally identifiable information.
This can be particularly useful for those that want to share confidential data sets with one another, but without the risk of de-anonymization (or re-identification) attacks.
According to Miguel Guevara, Product Manager, Privacy and Data Protection Office at Google, in a blog post:
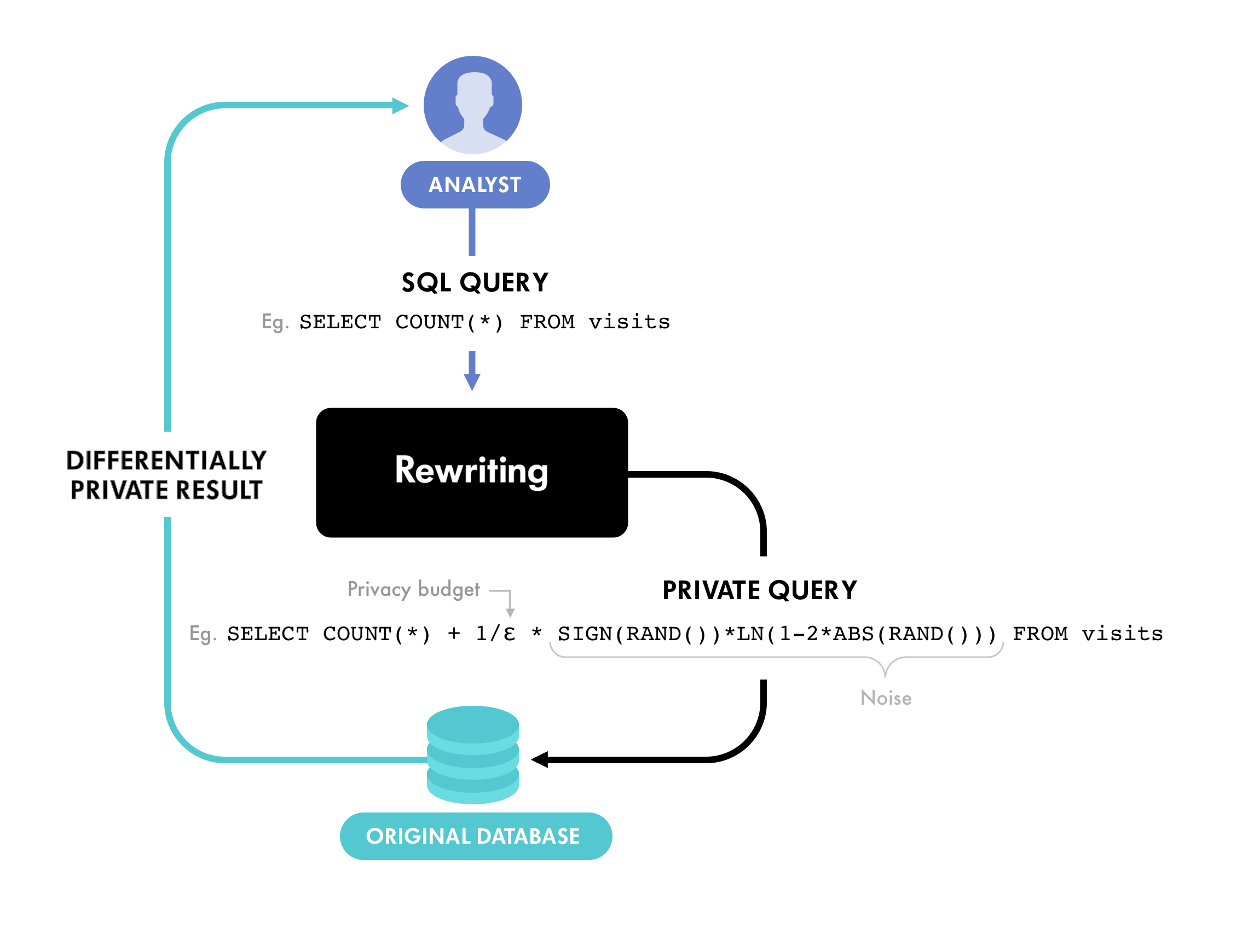
How DP works, is by strategically adding random noise to an individual’s information before it’s uploaded to the cloud.
This makes the total data set to be not exact, but still can reveal meaningful results - accurate enough without having to decrypt that individual’s sensitive data.
This tool essentially allows organizations to perform differentially private aggregations on databases. In addition to allowing multiple records to be associated with an individual user, “developers can compute counts, sums, averages, medians, and percentiles using our library,” Google explained.
The goal of DP is not data minimization, because it won’t stop companies from scooping personal data. Rather, it’s more about preventing the leak of sensitive information when inferring patterns through data mining techniques.
Similar technique is used by Apple to statistically anonymize iPhone user data using machine learning algorithms. Uber also has its own DP, called FLEX, which is used to limit queries from revealing too much about any individual Uber rider or driver.
By open-sourcing the the tool, Google not only wants to improve its offering, as it also hopes to help the community.
“From medicine, to government, to business, and beyond, it’s our hope that these open-source tools will help produce insights that benefit everyone,” said Guevara.
With the tool, Google that wants to avoid more intense scrutiny by regulators, also plans to leverage DP as part of its proposal for the anti-tracking policy, a move that has provoked criticism from privacy advocates.