

Since the introduction of photography, people always want to create better and better pictures.
After digital cameras come to life, photography has become a lot easier. And later, when AI was introduced, algorithms work to understand images and tweak them to make them appear better. As a result, people can just hit that shutter button and end up with great pictures.
But there is one thing that is proven to be difficult, and that is deblurring.
Image deblurring has long been a problem in the field of computer vision and image processing.
Blurry images can be results of motion, focal-blurred input image, camera shake, object motion or out-of-focus, and others. To deblur means to sharpen the image with necessary edge structures by adding details.
This is what the Chinese tech giant Tencent wants to achieve.

In a paper titled the "Scale-recurrent Network for Deep Image Deblurring," Tencent said that its solution has a simpler network structure than previous learning-based approaches.
Because it uses a smaller number of parameters, the researchers could train the AI better and faster.
"We evaluate our method on large-scale deblurring datasets with complex motion. Results show that our method can produce better quality results."
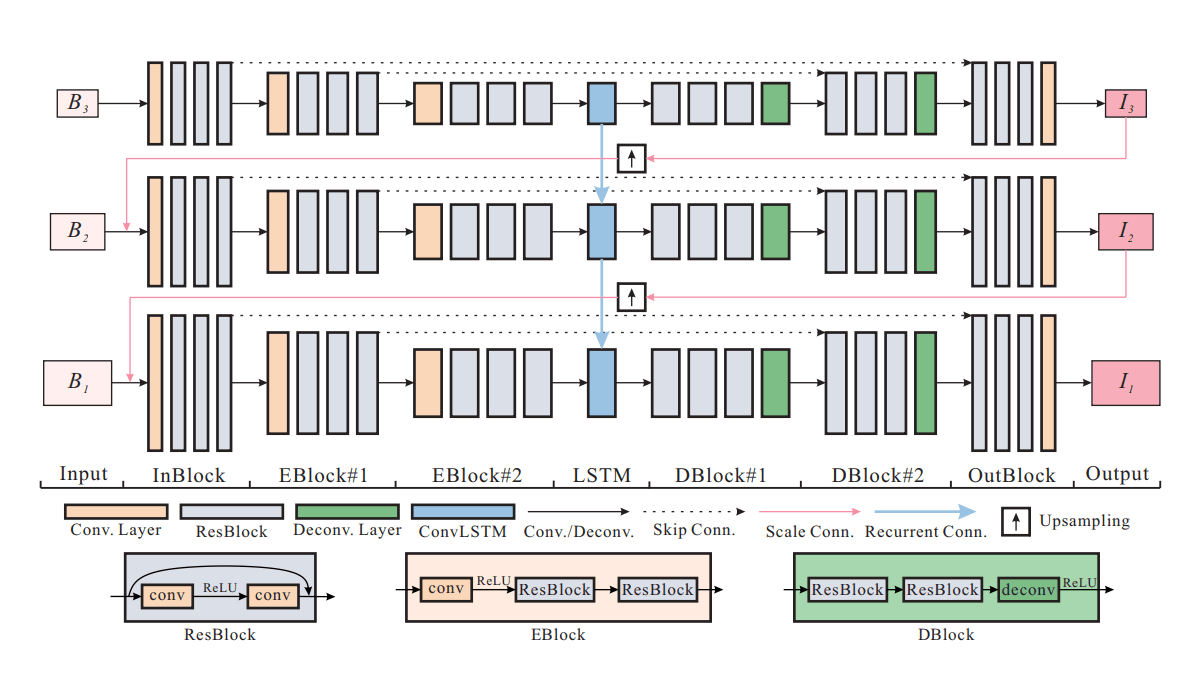
In its proposed framework, Tencent suggest several modifications should be made to adapt the encoder-decoder networks. This is by introducing residual learning blocks.
The image above illustrates how the proposed Encoder ResBlocks (EBlocks) contains one convolution layer followed by several ResBlocks. Tencent chooses ResBlocks instead of the original building block in ResN, and without batch normalization.
It also shows that Tencent doubles the number of kernels of the previous layer and downsamples the feature maps to half size.
Each of the following ResBlocks contains 2 convolution layers with the same number of kernels. The Decoder ResBlock (DBlocks) which is symmetric to EBlock, contains several ResBlocks followed by 1 deconvolution layer.
Then to scale-recurrent structure, Tencent requires recurrent modules inside networks, where it inserts convolution layers in the bottleneck layer for hidden state to connect consecutive scales. Then using large convolution kernels of size 5×5 on every convolution layer, the AI searches for hidden state that may contain useful information about intermediate result and blur patterns.
The results are then passed to the next scale and benefits the fine-scale problem.
In its experiment, Tencent used a PC with Intel Xeon E5 CPU and Nvidia Titan X GPU. Using TensorFlow platform, all the training process involved the same dataset with the same training configuration. The dataset includes synthesize blurred images by convolving sharp images with real or generated uniform/non-uniform blur kernels.
However, due to the simplified image formation models, Tencent acknowledged that the synthetic blurry data is still different from real blurry ones that are captured by cameras.