
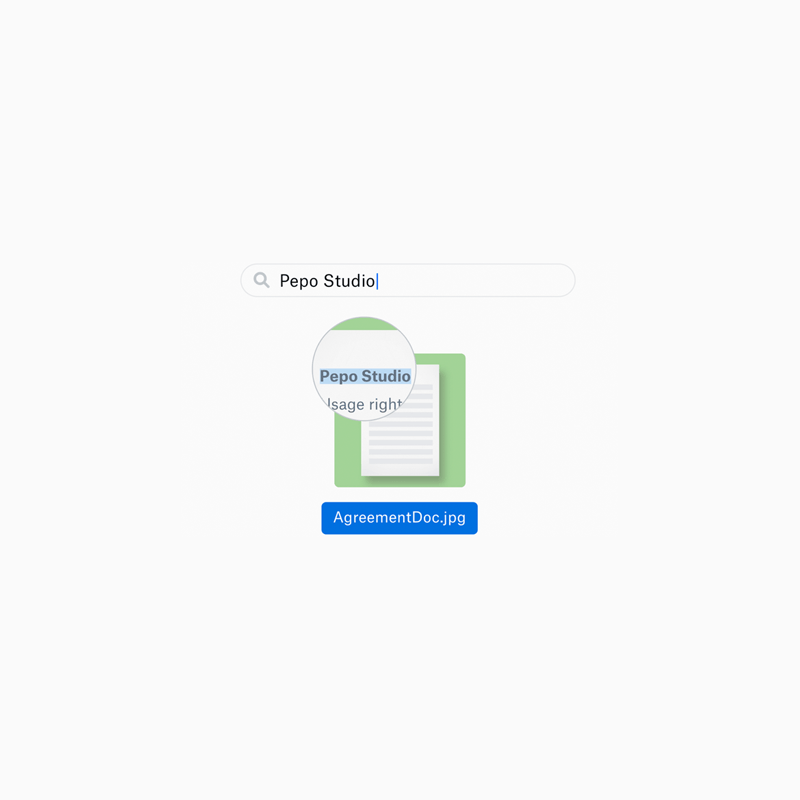
Text can be written inside anything. With Dropbox hosting more and more files, it starts seeing it increasingly necessary to be able to scan certain files for text.
The cloud-based file sharing and storage service has been building its own automatic text recognition, which allows users to search for text inside the files they've uploaded to the service. This feature extracts texts from photos and other files, and make them searchable.
According to the company, there are 20 billion image and PDF files stored on Dropbox. And since 10 to 20 percent of those are photos of documents, the Optical Character Recognition (OCR) capabilities should be very helpful indeed.
Initially available for Dropbox Business Advanced and Enterprise users, the feature works with English text.
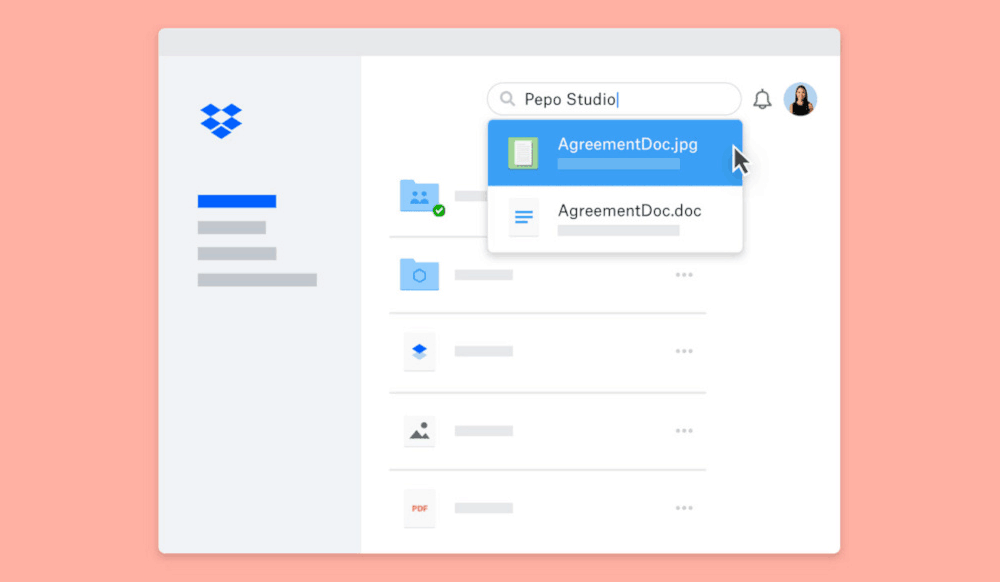
So now, when a user searches for English text that appears in one of these files, it will show up in the search results."
To make this possible, Dropbox is implementing its OCR capabilities directly into its search engine. This way, Dropbox users can search text within files that have been added in the past, no matter how they were scanned or photographed.
Supported formats include: .doc, .docx, .docm, Paper docs, .gif, .jpg, .pdf, .png, .ppt, .pptx, .pptm, .rtf, .tiff, .txt, .xls, .xlsx and.xlsm.
The company says this Dropbox search feature should make a huge difference to users.
The only limitation of this functionality is the computing-incentive nature of OCR process. What this means, Dropbox's search engine needed to be adjusted to impose this important limitation.
For example, PDF documents can have a lot of pages. For Dropbox OCR and search engine, processing all those files to seek specific words requires a lot of computing power, and should be indeed costly.
"Fortunately, for long documents, we can take advantage of the fact that even indexing a few pages is likely to make the document much more accessible from searches. So we looked at the distribution of page counts across a sampling of PDFs to figure out how many pages we would index at most per file. It turns out that half of the PDFs only have 1 page, and roughly 90% have 10 pages or less." explained Dropbox.
"So we went with a cap of 10 pages—the first 10 in every document. This means that we index almost 90% of documents completely, and we index enough pages of the remaining documents to make them searchable."
Previously, Dropbox has used similar OCR technology capable of scanning text from its document scanner app. This functionality however, only worked on a small subset of users' documents.
Related: Dropbox's Full-Text Search Engine 'Nautilus' Replaces Its Old 'Firefly' Search Engine