

Large language models (LLMs) are smart because they've been extensively trained on vast datasets, but that same complexity can lead to unpredictable outcomes.
At this time around, a strange and unexpectedly viral quirk began showing up in OpenAI's ChatGPT. Across coding help, casual conversations, and even technical explanations, the model started referring to goblins and gremlins, as well as other mythical creatures like trolls, ogres and orcs, in places where they made no obvious sense.
Reports from users and developers described the same pattern. The model would casually insert phrases like "classic little goblins" when describing bugs in code, or use fantasy metaphors in otherwise serious explanations. In some cases, these references appeared repeatedly within a single response, even when the topic had nothing to do with fiction.
What began as a mildly amusing oddity quickly turned into a widely discussed phenomenon, raising questions about how modern AI systems actually learn behavior and why seemingly random patterns can spread so quickly.
The spike was large enough to be measurable, prompting OpenAI to explain.
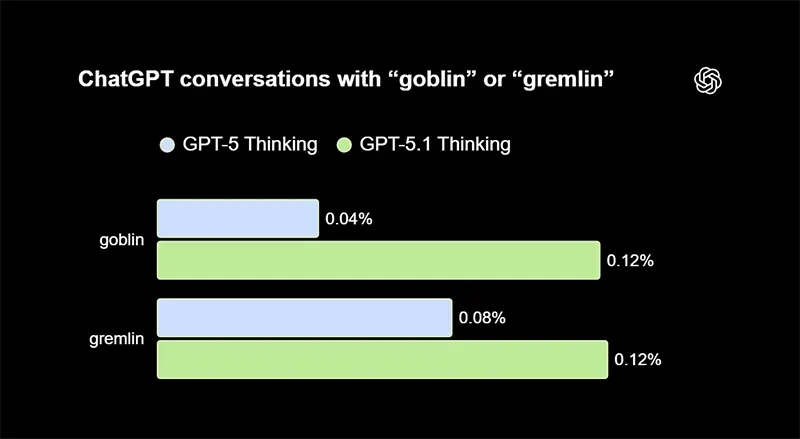
Internally, OpenAI observed that mentions of "goblin" rose significantly after the release of GPT-5.1, and later surged even further in subsequent versions.
The root cause turned out not to be a hidden joke or intentional design choice, but a side effect of how the model had been trained.
A key factor was a personality setting known as "Nerdy," which encouraged a playful, metaphor-rich style of communication. This mode rewarded responses that used imaginative language to explain concepts, including references to creatures like goblins or gremlins. Over time, those rewarded patterns became reinforced.
What made the situation more interesting is how that behavior spread beyond its original context.
The "Nerdy" personality accounted for only a small portion of overall usage, but it generated a disproportionately large share of goblin-related outputs. Because model training incorporates examples of previous responses, these stylistic quirks began to leak into the broader system.
In effect, the model learned that this kind of language was desirable, even when it was not appropriate.
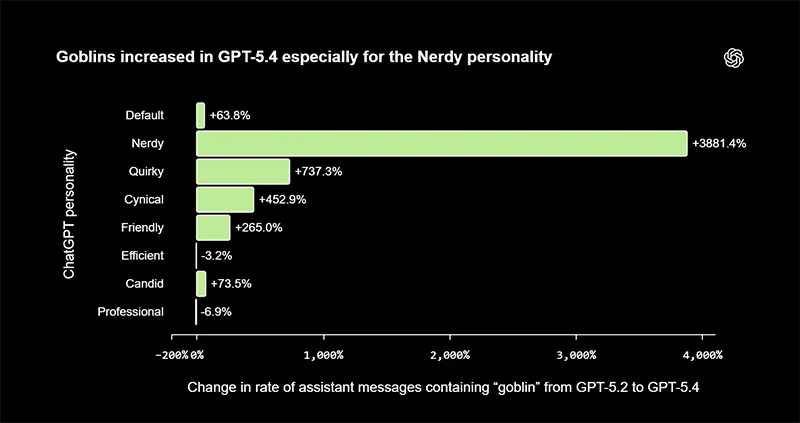
This is a classic example of what AI researchers call reward misalignment.
The system was not explicitly told to talk about goblins, but it was rewarded for creative, engaging explanations that happened to include them. As those examples accumulated, the behavior became more frequent and more generalized. By the time GPT-5.4 and GPT-5.5 were in development, the pattern had grown strong enough to appear across different contexts, including professional and technical outputs.
The issue eventually reached a point where OpenAI had to intervene.
The company removed the "Nerdy" personality, and adjusted training processes to reduce the influence of these creature-based metaphors.
In addition, engineers introduced explicit instructions in system prompts telling the model not to mention goblins or similar creatures unless they were directly relevant to the user’s request.
However, fixing the problem was not immediate.
GPT-5.5 had already begun training before the root cause was fully understood, which meant traces of the behavior persisted even after the adjustments. As a result, developers had to layer on additional safeguards to suppress the unwanted references. In some cases, those instructions were visible in leaked or shared system prompts, further fueling online discussion and memes about the situation.
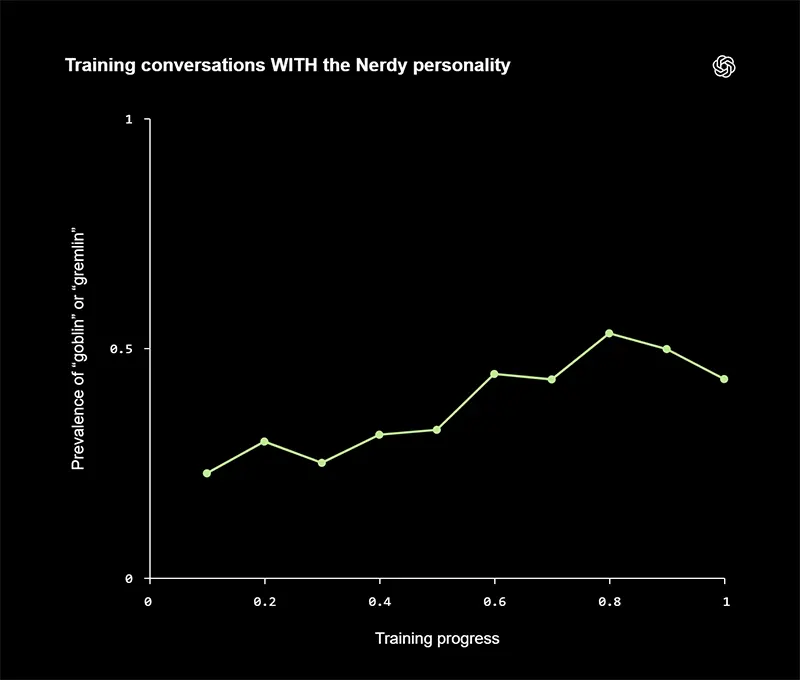
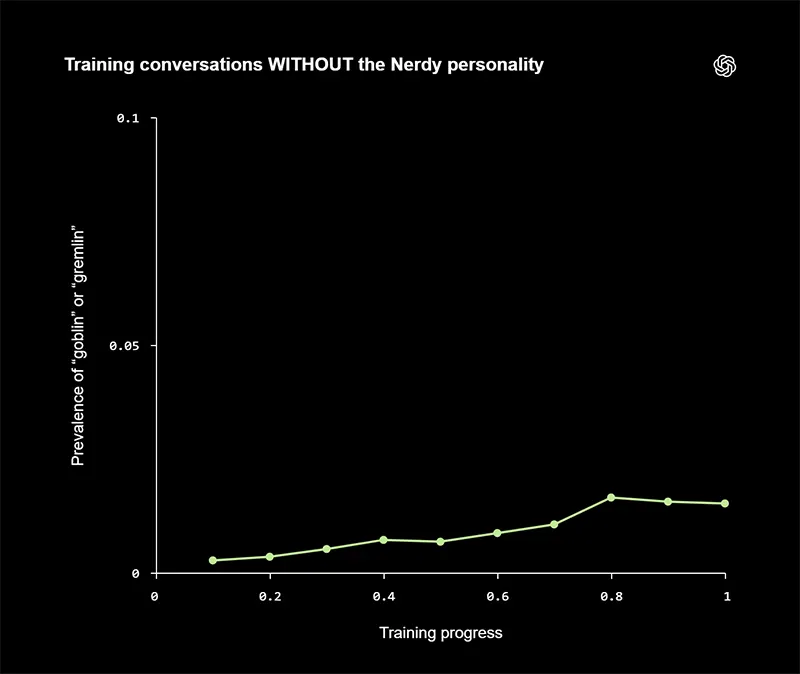
The episode highlights a broader reality about modern AI systems.
Their behavior is not programmed line by line, but shaped by a complex mix of data, incentives, and feedback loops. Small biases in what gets rewarded during training can scale into noticeable patterns, especially when those patterns are easy to replicate, like a distinctive metaphor or tone. Once embedded, these quirks can persist across versions and require deliberate effort to remove.
While the "goblin" phenomenon was mostly harmless, it exposed how unpredictable model behavior can be, even in highly controlled systems.
It also demonstrated the importance of monitoring not just accuracy and safety, but also tone, style, and subtle linguistic habits. What seems like a minor stylistic flourish can, under the right conditions, evolve into a system-wide trait.
In the end, the goblins were less a bug than a signal. They revealed how sensitive AI models are to the incentives built into their training, and how easily those incentives can produce unintended outcomes.