
Smartphones can have noise cancelling feature that reduces unwanted sound by adding a second sound that is specifically designed to cancel the first.
But separating users' voice with other people's voice and background noise can involve more than just that, as the matter can be more complicated than what it seems. Google has a powerful and capable voice-recognition AI. But it can be rendered useless if it can't listen to what its user is saying.
Google is expecting more human-computer interaction with voice.
This is exceptionally true, as voice commands are slowly gaining prevalence as an increasing number of people realize that it is an easy and intuitive way to get answers for their query, ask smart devices to perform a task and more.
This is why itneeds to come up with better ways to separate unwanted noises from what it really needs to hear.
To overcome these challenges, Google’s AI team has built a new lightweight model called 'VoiceFilter-lite'.
It began back in 2018, when Google unveiled VoiceFilter, which according to its publication, is "a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker."
Google managed to achieve this by training two neural networks: a speaker recognition network that produces speaker-discriminative embeddings; and a spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask.
"Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals," explained Google.
Google uses this VoiceFilter model in services like Google Assistant to analyze users' speech and sound.
But in order for this technology to work efficiently, in order to achieve better source-to-distortion ratio (SDR), the model requires a massive amount of CPU power and battery consumption.
That’s why Google came up with the VoiceFilter-lite.
The AI model that’s only 2.2MB in size is making it suitable for tons of lightweight mobile applications.
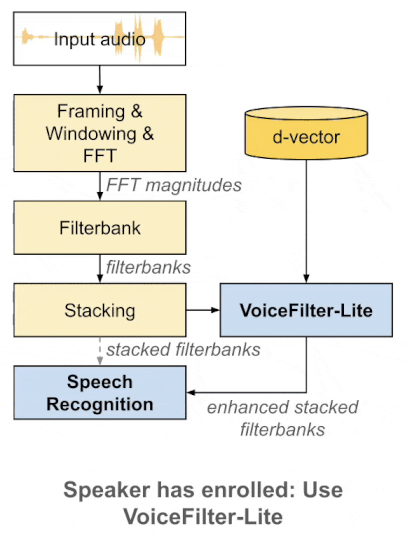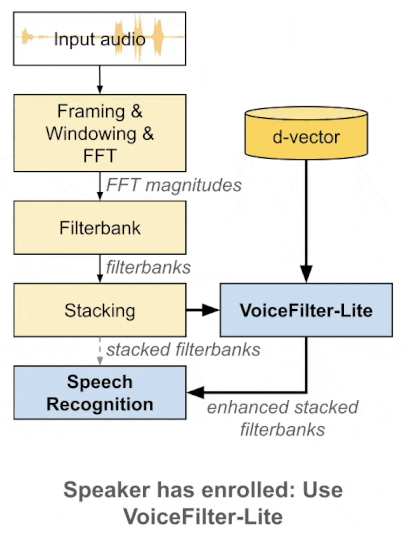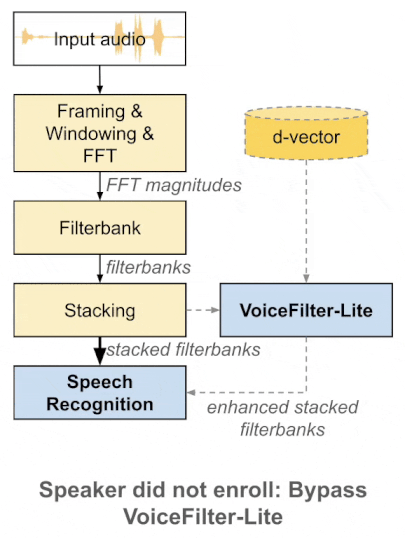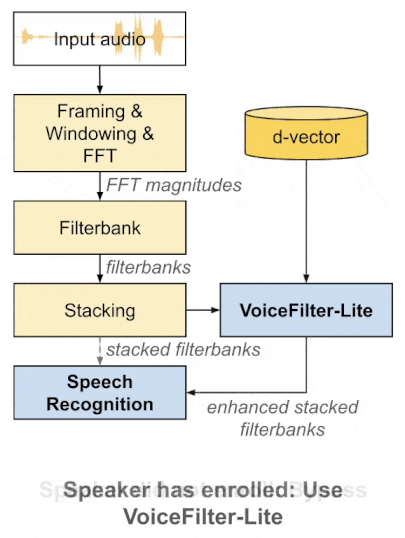
VoiceFilter-lite uses the already enrolled voice of a user, and improves the recognition even when there is an overlapped speech. That according to the researchers' paper.
According to Google, the AI is capable of enhancing voice recognition by 25% word error rate. Or also called WER, it's a ratio used to measure how many words a model recognizes from reference sentence.
Google realized that the AI could work faster and more efficient if it could work on users' device. What this means, it could work when users are using Incognito, and also when the device is offline.
In short, VoiceFilter-lite should be able to identify and work with a user’s voice even in ‘extremely’ noisy conditions, and even when internet connection is not available.
Due to its very small size, VoiceFilter-lite doesn't require developers to include it in their speech recognition model. So even when a speaker's voice wasn't enrolled previously, VoiceFilter-lite can ensure that apps can bypass it and carry on with recognition commands.
Initially, the model can only work for speakers speaking English.
As for the next steps, the researchers at Google want to apply this model to more languages. They also want to improve its direct-speech recognition so the model can be used for more than recognizing voices from overlapping speeches.
In a blog post, Google said that:
























































































































































































































































































































































































