

When two people meet, they can often predict what will happen next. That's obvious. But observers can also predict what will happen: a handshake? A hug? Or a kiss? Humans are able to anticipate actions based on experience and also knowledge.
This ability doesn't apply to machines. Artificial Intelligence is born out algorithms, and they have trouble in "understanding" complex actions like those.
In June 2016, researchers at the MIT's computer Science and Artificial Intelligence Laboratory (CSAIL) have made a breakthrough in creating predictive vision and developing an algorithm that makes robots able to anticipate human reactions more accurately than ever before.
The team trained the AI by showing it YouTube videos and TV shows, such as The Office and Desperate Housewives. By learning from the many human interactions, the system can then predict whether two of the actors/actresses will handshake, hug, kiss or doing a high-five.
In another scenario, the system can also predict what object will likely to appear in a video, five seconds before it comes to the camera.
"Humans automatically learn to anticipate actions through experience, which is what made us interested in trying to imbue computers with the same sort of common sense," said says CSAIL's PhD student Carl Vondrick.
Pattern Classification For Prediction

Previously, there were attempts to make computer have visions for predictions. Two of the approaches were:
The first method was to observe the image's individual pixels. The result from the process data was then used to create a photorealistic "future' image, pixel by pixel. This task, as described by Vondrick, was as "difficult for a professional painter, much less an algorithm."
The second method was to have humans labeling the scenes for computers to see in advance. This method was proven to be impractical for actions on a large scale.
As a new attempt, the team at CSAIL created an algorithm that can predict "visual representations" instead. This is basically freeze-frames showing different versions of what might be the future scenes.
To enable the AI for such feat, the algorithm makes use techniques from deep learning and neural networks to teach computers massive amount of data so they can find patterns on their own.
Each of the algorithm’s networks predicts a representation is automatically classified as one of the four actions (handshake, hug, kiss, high-five). The system then merges those four actions into one that it can use as its prediction.
The Future Of Its Future
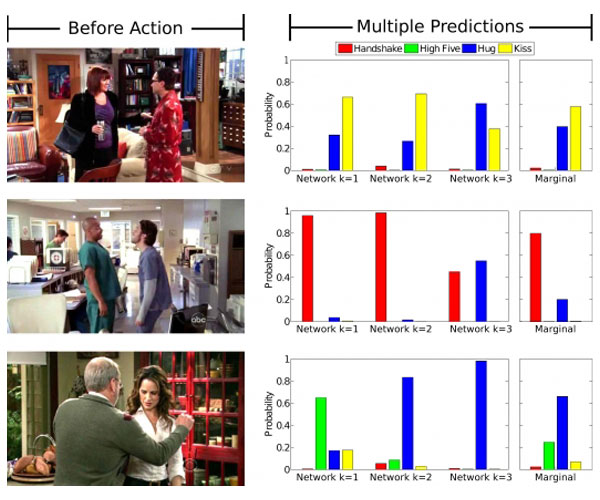
After the team trained the algorithm using 600 hours of videos, the team then tested it on new videos showing both actions and objects. The result is quite remarkable that the AI can predict actions more than 43 percent correct at a time. This is a gain from previous attempts that could only do 36 percent at a time.
After training the algorithm on 600 hours of unlabeled video, the team tested it on new videos showing both actions and objects.
And as for predicting what object will show in the future, the algorithm was shown a frame from a video, for example, seeing someone opening a microwave. The algorithm might suggest the future presence of a mug. The algorithm predicted the object 30 percent more accurately than baseline measures, with an average accuracy of 11 percent.
In a second study, the algorithm was shown a frame from a video and asked to predict what object will appear five seconds later.
For example, seeing someone open a microwave might suggest the future presence of a coffee mug. The algorithm predicted the object in the frame 30 percent more accurately than baseline measures, though the researchers caution that it still only has an average precision of 11 percent.
Here we see that the algorithms are far from perfect, yet alone accurate for practical applications. By as Vondrick said, the future versions could be used for everything from robots that develop better actions plans to security camera that can alert emergency responders when it sees someone has fallen or got hurt.
While the algorithms aren’t yet accurate enough for practical applications, Vondrick says that future versions could be used for everything from robots that develop better action plans to security cameras that can alert emergency responders when someone who has fallen or gotten injured.
When 600 hours of videos already made a huge advancement, Vondrick said that he was excited to see how much the algorithms can get better if we feed them a lifetime worth of videos. In the future, as he predicted, we might see some significant improvements where robots can use its predictive-vision to really aid humans.
The work was supported by a grant from the National Science Foundation, along with a Google faculty research award for Torralba and a Google PhD fellowship for Vondrick.