
They say AI is as smart as the data it’s trained on. But what if it could explore the web in real-time and provide answers in the most convincing ways?
That’s exactly the promise large language models (LLMs). Since ChatGPT was launched and others followed with their own products and solutions, many eventually realized that to make AIs smarter and more capable of answering questions, is by making them capable of browsing the web.
By making chatbots capable of searching the web on demand, they become more than just an assistant that rely solely on static training. Instead, they can fetch fresh headlines, dig through the deepest underbellies of forums, and pull up latest research in just seconds. Letting AI browse freely makes it more useful—more current, more aware, more helpful. But it also makes it vulnerable to misinformation, manipulation, and ethical landmines.
After all, the internet isn’t a library; it’s a jungle.
While LLMs certainly benefit from having this ability, not everyone like to have their websites indexable by crawlers. Not all website owners want their content and everything within it become training materials for some AI companies.
This is why websites can block them through exception rules.
Good crawlers obey. Bad crawlers don't.
And Perplexity is the second. And according to Cloudflare that revealed this, its CEO, Matthew Prince, even went as far as comparing it to some "North Korean hackers."
Read: How Cloudflare Wants To Disrupt The Scrapings Of AI Crawlers Using A 'Pay-Per-Crawl' Business Model
Some supposedly “reputable” AI companies act more like North Korean hackers. Time to name, shame, and hard block them. https://t.co/vqMzGRHZPf
— Matthew Prince (@eastdakota) August 4, 2025
Cloudflare is a web infrastructure and security company, which acts like a seductive, silent guardian of the internet, standing between websites and the chaotic mess of bots, hackers, and malicious traffic.
Founded in 2009, Cloudflare started with a mission: to help build a better internet. Now, it's one of the biggest names in CDN (Content Delivery Network), DDoS protection, DNS services, zero-trust security, and edge computing. Over 20% of global internet traffic flows through its network.
And this time, its researchers found that Perplexity has been browsing the web to power its AI-powered answer engine.
To do this, Cloudflare alleges that Perplexity conducts "stealth crawling behavior," where its crawlers crawl using their declared user agent, but when the crawlers are presented with a network block, they can obscure their crawling identity to bypass the blockage.
"We see continued evidence that Perplexity is repeatedly modifying their user agent and changing their source ASNs to hide their crawling activity, as well as ignoring — or sometimes failing to even fetch — robots.txt files," Cloudflare said in a blog post.
Cloudflare ran an experiment after receiving complaints from customers who had explicitly blocked crawling activity from Perplexity.
These customers had configured their sites to disallow access to both of Perplexity’s declared crawlers: PerplexityBot and Perplexity-User, and had even set up Web Application Firewall (WAF) rules to enforce the block. Despite these measures, they reported that Perplexity was still able to access their content, even though logs showed that its bots were being successfully blocked.
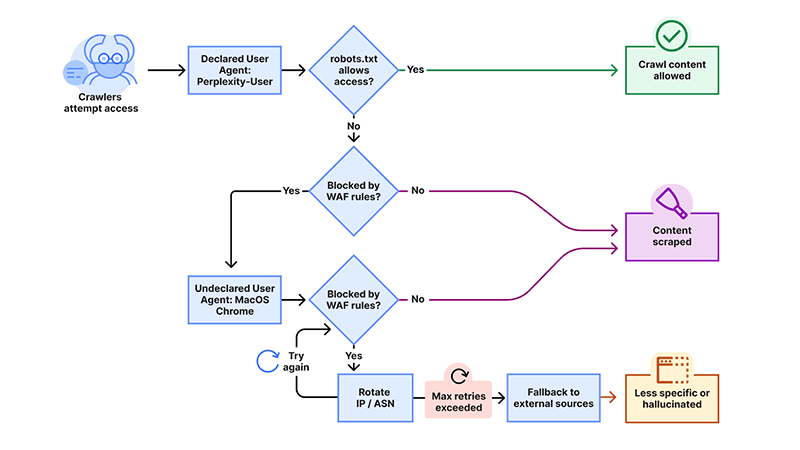
Cloudflare ran tests across several controlled domains that explicitly disallowed automated access, just like what the customers did.
Despite these safeguards, Perplexity was indeed still accessing content.
This is where Cloudflare alleged that the two declared user-agents that identified themselves openly as affiliated with Perplexity and was responsible for an estimated 20 to 25 million requests per day. Cloudflare found that when these agents were blocked, the agents started mimicking other agents, like Google Chrome on macOS.
This stealthy agent appeared far more generic and made it significantly harder to identify as a bot. It was responsible for an additional 3 to 6 million daily requests.
The undeclared crawler was especially evasive because it used multiple IP addresses not found in Perplexity’s official documentation and rotated them frequently in response to blocks. Traffic was also seen originating from a range of different Autonomous Systems (ASNs), likely an attempt to bypass site defenses and remain undetected.
And if the two aforementioned methods still couldn't make the crawlers through their destined target, Perplexity appeared to rely on secondary data sources, including unrelated websites, to generate answers.
These fallback responses lacked the richness and specificity of answers generated from directly scraped content, confirming that effective blocking had a real impact on the quality of their output.
In response to Cloudflare's accusation, Perplexity denied any wrongdoing, attributing the allegations to misunderstandings and distancing itself from certain IPs cited by Cloudflare.
The bluster around this issue reveals that Cloudflare’s leadership is either dangerously misinformed on the basics of AI, or simply more flair than cloud. https://t.co/NgliGZCspP
— Perplexity (@perplexity_ai) August 5, 2025
Projects like Perplexity, OpenAI’s browsing models, and even Google’s Gemini are exploring this frontier. Cloudflare's finding shows that giving AI open access to the web raises questions that aren't just about technological capability but also about ethics, control, and respect for digital boundaries.
While AI-powered tools promise faster, smarter access to information, their crawling behavior often bypasses long-established norms meant to protect site owners, such as robots.txt directives and rate limits. This creates an imbalance: small publishers and independent creators risk having their content extracted and repurposed without consent, compensation, or even visibility.
Cloudflare’s discovery highlights a deeper issue: some AI systems may not just rely on their declared crawlers, but also deploy stealth techniques to access data. This includes rotating IPs, spoofing user-agents, and sidestepping restrictions, effectively undermining web transparency. It raises the question: how can the internet remain open and useful for AI without turning it into a free-for-all that disregards creators’ rights?
As generative AI becomes increasingly integrated into search, research, and productivity tools, the stakes are rising.
Content scraped without permission fuels models that may answer user queries without ever directing traffic back to the original source. It's a shift from the hyperlink economy to a harvest-and-respond ecosystem, where the original web becomes invisible, yet essential.
There’s no denying the future includes AI that reads the web. But who decides the rules of engagement? Cloudflare’s findings are a timely reminder that the web wasn’t built for unaccountable bots.

























































































































































































































































































































































































