
Google is trying to change the course of search in a fundamental way, marking the first major upgrade to its iconic search box in over 25 years.
At the recent Google I/O 2026 conference, the company unveiled a sweeping redesign that transforms the simple text field into a dynamic, intelligent interface capable of handling conversational prompts, images, videos, files, and even open Chrome tabs.
By merging AI Overviews with AI Mode and introducing advanced agents powered by the latest Gemini models, Google aims to shift users away from scanning lists of links toward a more proactive experience where the AI summarizes information and delivers answers directly.
Yet this ambitious rollout has quickly run into an embarrassing setback.
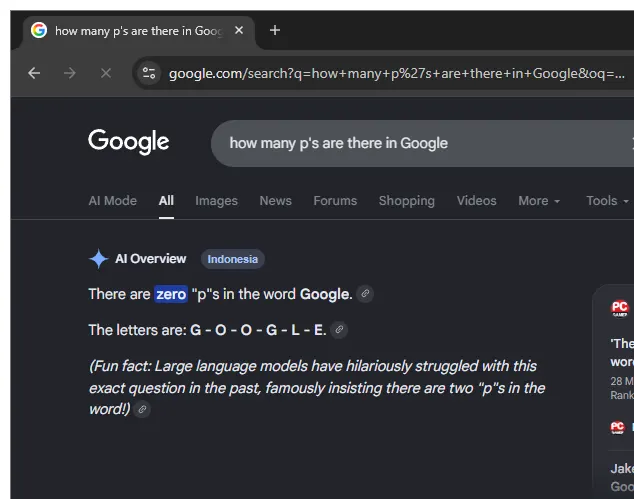
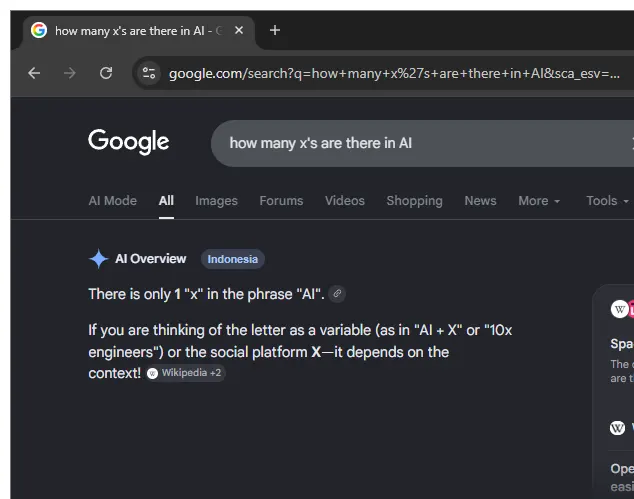
Users have discovered that the upgraded AI Overview is struggling with basic spelling and letter-counting tasks, producing errors that spread rapidly across social media.
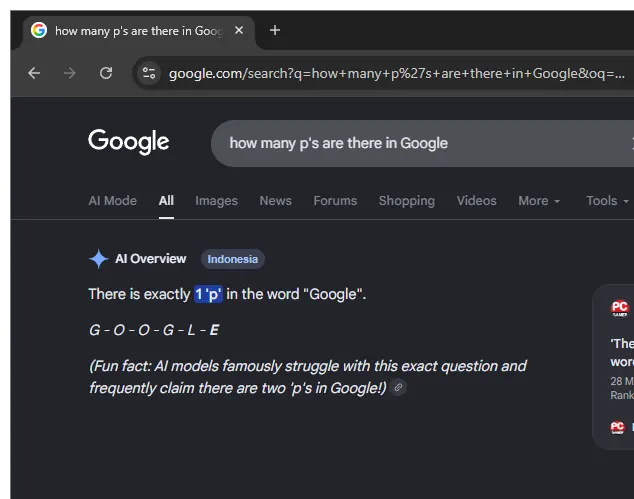
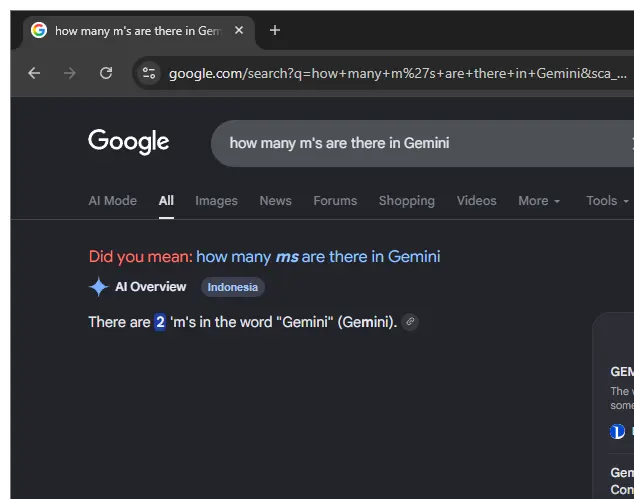
When asked how many P's appear in the word Google, the system has responded that there are two, an ironic mistake given the company's own name contains just one. Similar glitches have appeared with its own AI product, as the Overview claimed there are two Ms in Gemini. Reports also show the AI adding extra letters to other words, such as suggesting two Ds in journalism while spelling it incorrectly as j-o-u-r-n-a-d-i-s-m, or mangling the name of the U.S. president into t-r-p-u-m.
These mistakes highlight a deeper limitation in how large language models operate.
Instead of reading text character by character like humans do, LLMs convert input into numerical tokens that represent whole words, syllables, or subword chunks rather than individual letters.
When a prompt is entered, the text is translated into encodings that capture meaning at a higher level, so the model never truly sees the separate letters that make up a word.
For example, it might recognize the encoding for the entire word Google without any awareness of the sequence G-o-o-g-l-e.
The flaw happens to reside on the LLM's transformer architecture, which notably is not actually reading text.
What happens when users input a prompt is that it is translated into an encoding.
When it sees the word "the," for example, it has this one encoding of what the means, but it does not know about T, H, E. This token-based system stems from the transformer architecture at the heart of modern LLMs, which prioritizes statistical patterns and contextual prediction over precise character-level manipulation.
Then, then fuzziness of tokenization makes perfect accuracy difficult, noting there is no such thing as a perfect tokenizer due to this kind of fuzziness.
As a result, tasks that require granular letter awareness, such as counting specific letters inside a word or spelling them out accurately, become inherently challenging because the models were never designed primarily for that kind of low-level string processing.
Because fo these reasons, spelling mistakes like these have become oddly familiar in the age of AI.
For years, people have joked that the quickest way to test a new AI model is to ask how many Rs are in the word "strawberry." These systems can write code in seconds and tackle problems that challenge expert mathematicians, yet when it comes to spelling, they can perform with the confidence of a kindergartener.
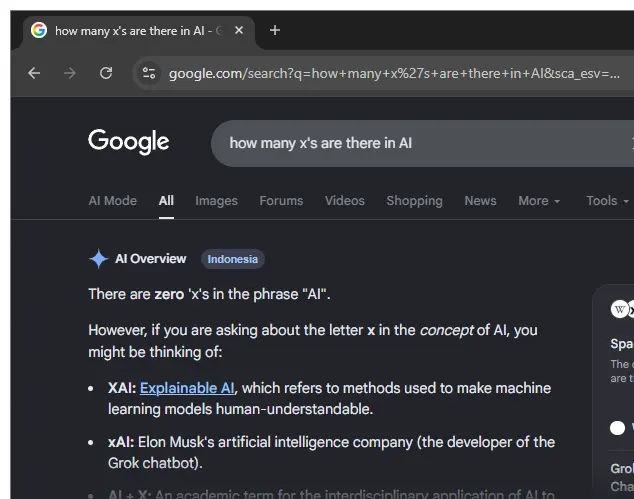
What makes the problem particularly noticeable is its inconsistency.
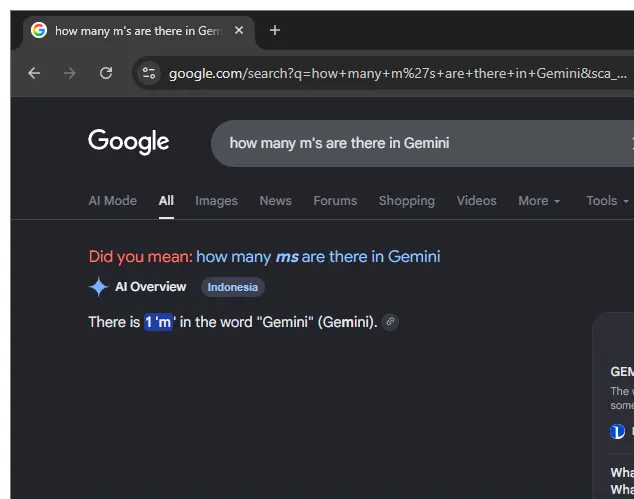
Sometimes the AI Overview gets the count right, while other times it fails on the exact same query. Users have even observed that simply refreshing the web page can occasionally produce a correct answer for the identical question.
This variability stems from the probabilistic nature of LLMs: they generate responses based on statistical patterns learned during training rather than performing deterministic calculations.
When a word or similar letter-counting example has appeared frequently and correctly in the training data, the model may produce the right answer through pattern matching or lucky alignment of tokenization in that specific context.
Slight differences in phrasing, the surrounding prompt, internal sampling, or even the exact moment the query is processed can shift how the input is chunked into tokens, leading to different outcomes each time.
Errors tend to increase with longer words or when letters repeat multiple times, as the complexity of the counting operation itself overwhelms the model's higher-level representations. In short, success is often coincidental rather than reliable, because the system is predicting what sounds right instead of truly examining each character.
Google has acknowledged the issue, stating in response that counting within words has been a known challenge for LLMs and that the company is working to fix this particular issue.
Researchers, however, are not optimistic about a complete solution because the limitations are baked into the fundamental design of these token-based systems. The timing feels particularly awkward because the errors surfaced right as the more prominent AI Overviews gained even greater visibility in search results following the I/O updates.
This latest incident follows a pattern of earlier AI Overview misfires, including cases where the system treated words like disregard as instructions to ignore prompts rather than providing definitions, or offered questionable advice on unrelated topics.
While the feature has improved overall and now reaches billions of users each month, these spelling blunders serve as a clear reminder that even sophisticated AI can falter on tasks that seem elementary to people.
As Google pushes forward with its vision for an AI-first search engine, the episode underscores the tension between rapid innovation and practical reliability.
Users benefit from faster answers and richer summaries, yet moments like these reinforce the need to double-check important details against primary sources.
The road ahead for search will likely involve ongoing refinements to bridge these gaps, balancing the excitement of new capabilities with the expectation that the system gets even the simplest facts right. In the meantime, the viral spelling errors have provided the internet with a moment of levity while highlighting that the journey toward truly dependable AI-assisted search is still very much in progress.