
The race is on, and it's not just about the West that thrives, because the East is catching up very fast.
Since OpenAI's introduction of ChatGPT, there is no denying that Americans remain in advantage in terms of having commercial, state-of-the-art, consumer AI product. But the East is not far behind.
China in particular, is extremely big, but so shielded from foreign influences.
This is giving huge advantage to Chinese companies.
Since China’s domestic market is largely censored, and that policies also prohibit non-vetted products to be used in the region, China literally leave a market of over 1 billion internet consumers open to local players.
And in the world where AI has taken the spotlight, DeepSeek is one of the smaller players that wish to compete in this lucrative industry.
After introducing DeepSeek-R1, an AI model that can reason, DeepSeek goes a step further by introducing what it calls the 'DeepSeek-V3'.
Introducing DeepSeek-V3!
Biggest leap forward yet:
60 tokens/second (3x faster than V2!)
Enhanced capabilities
API compatibility intact
Fully open-source models & papers
1/n pic.twitter.com/p1dV9gJ2Sd— DeepSeek (@deepseek_ai) December 26, 2024
And this AI model is nothing less than astonishing.
First of, instead of making it a reasoning AI model that competes against OpenAI o1 or Google Gemini 2.0 Flash Experimental, DeepSeek-V3 is more like a multi-purpose AI.
What this means, DeepSeek-V3 is a rival to OpenAI GPT-4o and Meta LLaMA 3.1, for example.
And surprisingly, the AI managed to defeat those two.
If that is not astounding enough, DeepSeek-V3 surpassed them by a long margin, while being open sourced.
The model was released under a permissive license that allows developers to download and modify it for most applications, including commercial ones.
In all, DeepSeek V3 can handle a range of text-based workloads and tasks, like coding, translating, and writing essays and emails from a descriptive prompt.
According to DeepSeek’s internal benchmark testing, DeepSeek V3 outperforms both downloadable, “openly” available models and “closed” AI models that can only be accessed through an API.
In a subset of coding competitions hosted on Codeforces, a platform for programming contests, DeepSeek-V3 also outperforms Anthropic Claude 3.5 Sonnet, among other powerful AI models.
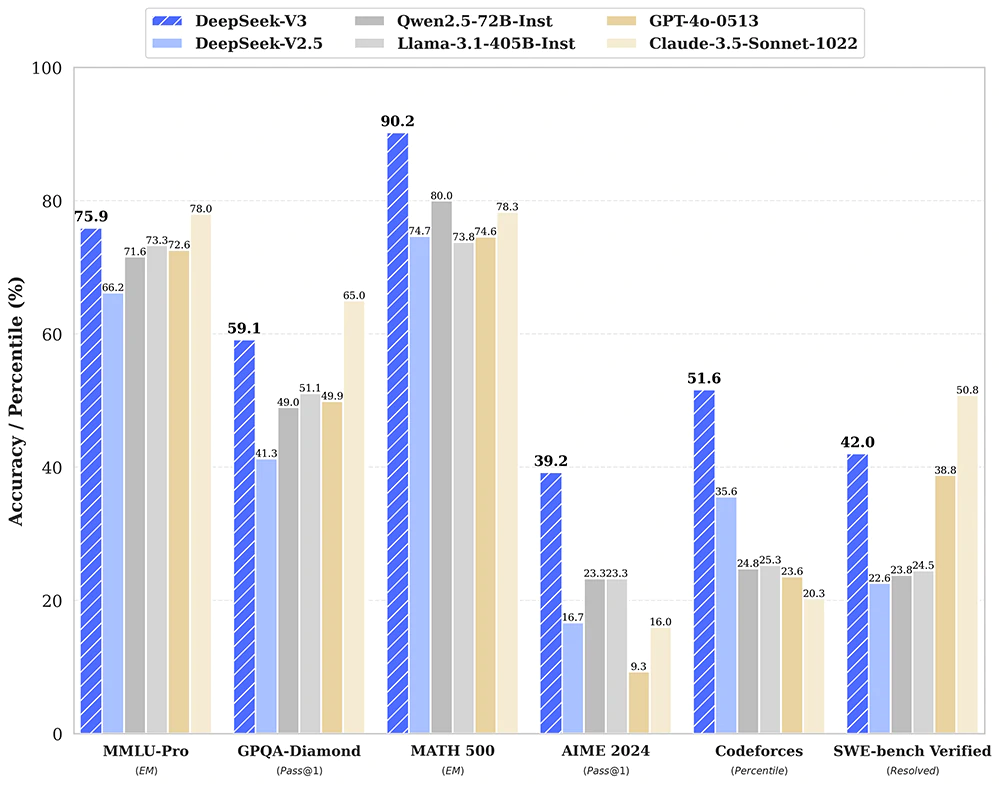
As for how it managed to achieve this, DeepSeek claims that DeepSeek-V3 was trained on a dataset of 14.8 trillion tokens.
It’s not just the training set that’s massive, because DeepSeek-V3 is enormous in size.
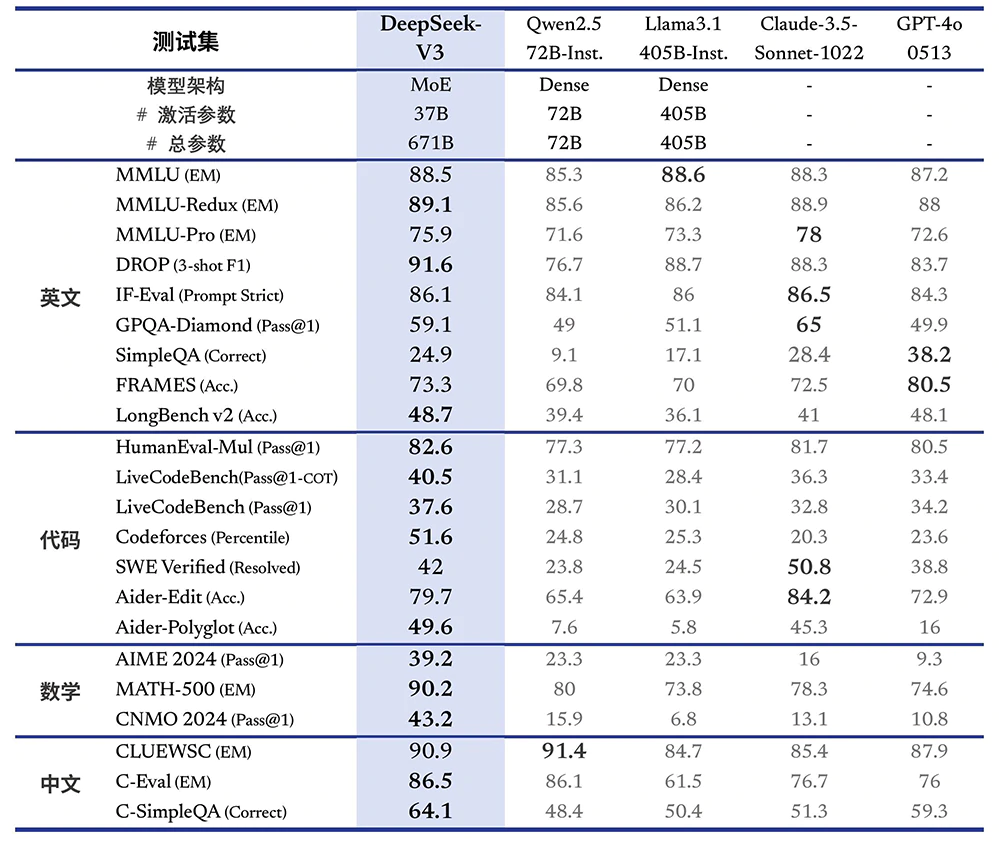
With 671 billion parameters, according to its webpage on Hugging Face, DeepSeek-V3 around 1.6x larger than LLaMA 3.1 405B, which has 405 billion parameters.
It's worth noting that because parameter count often correlates with skills, AI models with more parameters tend to outperform models with fewer parameters.
Since parameters are the internal variables models use to make predictions or decisions, higher usually translates to smarter.
Another achievement the DeepSeek achieved, is the resource needed to train the AI.
Large Language Models that power generative AI products like DeepSeek AIs and others require powerful hardware to run and learn. As for DeepSeek-V3, an unoptimized version of the AI required a bank of high-end GPUs.
Here, DeepSeek-V3’s entire training required only about 2788K H800 GPU hours, or about $5.57 million, assuming a rental price of $2 per GPU hour. This is much lower than the hundreds of millions of dollars usually spent on pre-training large language models.
This, is fraction of what OpenAI required when it trained the older GPT-4.
In comparison, LLaMA 3.1 is estimated to have been trained with an investment of over $500 million.
The company did this by introducing two innovations.
The first is an auxiliary loss-free load-balancing strategy, which dynamically monitors and adjusts the load on experts to utilize them in a balanced way without compromising overall model performance.
The second is multi-token prediction (MTP), which allows the model to predict multiple future tokens simultaneously. This innovation not only enhances the training efficiency but enables the model to perform three times faster, generating 60 tokens per second.
"During pre-training, we trained DeepSeek-V3 on 14.8T high-quality and diverse tokens…Next, we conducted a two-stage context length extension for DeepSeek-V3," the company wrote in a technical paper (PDF) detailing the new model.
"In the first stage, the maximum context length is extended to 32K, and in the second stage, it is further extended to 128K. Following this, we conducted post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeekR1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length."
Notably, during the training phase, DeepSeek used multiple hardware and algorithmic optimizations, including the FP8 mixed precision training framework and the DualPipe algorithm for pipeline parallelism, to cut down on the costs of the process.
The downside of this is that, DeepSeek-V3 lacks tremendously in politics, for example.
API Pricing Update
Until Feb 8: same as V2!
From Feb 8 onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
Still the best value in the market!
3/n pic.twitter.com/OjZaB81Yrh— DeepSeek (@deepseek_ai) December 26, 2024
Long story short, DeepSeek-V3 is essentially a "strong" Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token, which achieves efficient inference and cost-effective training.
The work shows that open-source is closing in on closed-source models, promising nearly equivalent performance across different tasks.
The development of such systems is extremely good for the industry as it potentially eliminates the chances of one big AI player ruling the game. It also gives enterprises multiple options to choose from and work with while orchestrating their stacks.
At this time, the code for DeepSeek-V3 is available via GitHub under an MIT license, while the model is being provided under the company’s model license.
Enterprises can also test out the new model via DeepSeek Chat, a ChatGPT-like platform, and access the API for commercial use.
Open-source spirit + Longtermism to inclusive AGI
DeepSeek’s mission is unwavering. We’re thrilled to share our progress with the community and see the gap between open and closed models narrowing.
This is just the beginning! Look forward to multimodal support and…— DeepSeek (@deepseek_ai) December 26, 2024