

Business is business. But when it comes to the development of technology in general, it's a collaborative work that no single entity can master.
In a race that happens after the boom of generative AI, thanks to the release of ChatGPT, tech companies like OpenAI, Google, Meta, as well as other smaller ones, are engaged in a competition, where they build more powerful and capable Large Language Model AIs.
And here, the companies have been promoting the advanced "reasoning" capabilities of their AI models as the next major breakthrough.
While this doesn't necessarily mean that their AIs are AGIs, they have indeed showed the world how smart their products are.
But according to a study by six Apple engineers, it's revealed that the AIs's mathematical "reasoning" can be unreliable, even when facing small changes to standard benchmark problems.
This fragility the Apple researchers supports earlier research, which suggest that the "reasoning" capabilities of LLMs are largely based on probabilistic pattern matching rather than a true understanding of underlying concepts.
Read: Paving The Roads To Artificial Intelligence: It's Either Us, Or Them

In the pre-print paper, GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, the engineers began their research by conducting a GSM8K benchmark, which includes over 8,000 grade-school-level math problems commonly used to test LLMs.
But to test the AIs, they modified parts of this set, in order to dynamically changing names and numbers in the problems.
For example, a problem about Sophie with 31 building blocks became one about Bill with 19.
These changes, while insignificant to the actual math, is supposed to help prevent "data contamination," where the original GSM8K problems may already be in a model's training data.
However, LLMs see this as an added complexity.
Despite the unchanged math problem, the LLMs couldn't perform as good as when they're told to perform on the unmodified tests.
When the researchers conducted the research on more than 20 advanced LLMs, they saw a performance drop, with accuracy reductions ranging from 0.3% to 9.2% compared to the unmodified GSM8K set.
Some even performed with accuracy reduction of around 15%.
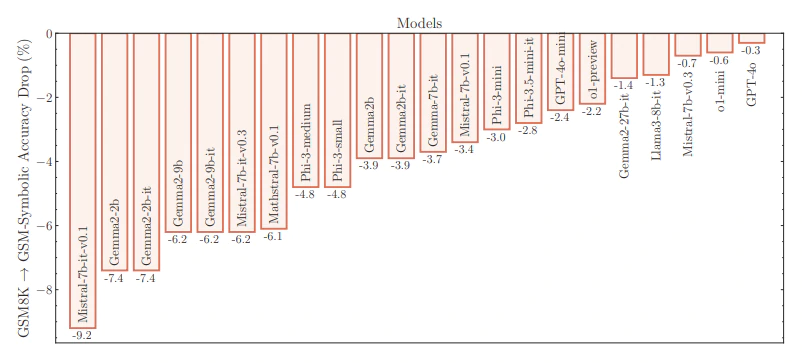
This variability surprised researchers.
What the researchers found here is that, LLMs are not engaging in true "formal" reasoning but are instead relying on pattern-matching to connect new problems to similar ones seen during training.
This is concluded because the tweaks they made didn't change the core steps to solve the problems.
While these fluctuations are notable, the overall impact was relatively minor for some models.
For instance, OpenAI's GPT-4 saw only a slight accuracy drop from 95.2% on GSM8K to 94.9% on the modified set, which means that the LLM is still having a strong overall performance.
This may come unnoticed, even for OpenAI itself.
However, many other models showed significant accuracy drops when just one or two extra logical steps were added to the problems. They even performed much worse when the researchers added irrelevant details to the problems, creating what they called the "GSM-NoOp" benchmark.
For example, a question about kiwi picking might be changed to include an unnecessary detail about some kiwis being smaller than average. This led to massive drops in accuracy, ranging from 17.5% and 65.7%.
This indicates that LLMs often misinterpret these distractions as meaningful, despite their irrelevance.
In cases like the smaller kiwis, many models mistakenly subtracted the number of smaller fruits from the total, likely because their training data contained similar examples requiring subtraction. The researchers called this a "critical flaw," showing the limitations of the models' reasoning abilities, which fine-tuning alone cannot fix.

This study from the researchers from Apple is part of a growing body of research showing that LLMs often don't engage in genuine reasoning, but instead mimic it by using probabilistic pattern-matching based on their training data.
The fragility of this approach becomes clear when the prompts deviate from familiar patterns, highlighting the limitations of current models.
Experts suggest that AI is far being "smart," in terms that it can be considered an AGI.
The next leap of AI may require a "symbol manipulation," which means that future AI should be able to understand knowledge it leaned abstractly, like in algebra or traditional programming.
Before this can happen, experts conclude that LLMs may continue showing brittleness in their reasoning capabilities.