

AI has become the technology behind numerous products, thanks to its ability to solve problems beyond their original programming.
And among the fields of AI, include AI for speech. This technology is able to convert normal language text into pronounce words, and pronounced words to text (TTS) using a technology that is called automated speech recognition (ASR).
Google has been in developing this kind of technology for a long time, and so does some others. Meta is also having its own speech AI.
During Nvidia’s Speech AI Summit, Nvidia, the chipmaker, discussed how AI has evolved.
And this time, the company also announced an AI ecosystem it developed through a partnership with Mozilla Common Voice.
The ecosystem focuses on developing crowdsourced multilingual speech corpuses and open-source pretrained models.
Nvidia and Mozilla Common Voice aim to accelerate the growth of automatic speech recognition models that work universally for every language speaker worldwide.

Mozilla Common Voice is a crowdsourcing project with a goal to create a free database for speech recognition software.
The project is supported by volunteers around the world who record sample sentences with a microphone and review recordings of other users. The transcribed sentences are then collected in a voice database that can be accessed publicly. This in turn should allow developers to use the database for voice-to-text applications without restrictions or costs.
And here, Nvidia wants to use its speech AI technology to enhance both ASR and TTS.
In a blog post, Nvidia said that examples include automatic live captioning in virtual meetings and adding voice-based interfaces to virtual assistants.
By announcing its own AI ecosystem project, Nvidia enters a competition that is already dominated by Google and Meta, which have both released speech AI models to aid communication among people who speak different languages.
Google has what it calls the Translation Hub, which is able to translate a large volume of documents into many different languages. Google is also building a universal speech translator, trained on over 400 languages, with the claim that it is the “largest language model coverage seen in a speech model today.”
Meta on the other hand, has an AI-powered universal speech translator, meant to enable real-time speech-to-speech translation across all languages, even those that are spoken but not commonly written.
It all began when Nvidia found that digital voice assistants, like Google Assistant, Amazon Alexa and Apple's Siri only support less than 1% of the world’s spoken languages.
To solve this problem, Nvidia wants to improve AI development using linguistic inclusion in speech AI, by expanding the availability of speech data for more languages, especially low-resourced languages that are less known or spoken.
According to Nvidia, linguistic inclusion for speech AI has comprehensive data health benefits.
For example, this can help AI models to better understand speaker diversity and a spectrum of noise profiles.
What's more, the ecosystem should also help developers build, maintain and improve the speech AI models and datasets, usability and also experience.
Users can train their AI models on Mozilla Common Voice datasets, and then offer those pretrained models as high-quality automatic speech recognition architectures. Then, others can adapt and use those architectures for building their speech AI applications.
According to Caroline de Brito Gottlieb, product manager at Nvidia:
"There are several vital factors impacting speech variation, such as underserved dialects, sociolects, pidgins and accents. Through this partnership, we aim to create a dataset ecosystem that helps communities build speech datasets and models for any language or context."
According to Siddharth Sharma, head of product marketing, AI and deep learning at Nvidia:
At this time, the Mozilla Common Voice platform supports 100 languages, with 24,000 hours of speech data available from 500,000 contributors worldwide.
Through the Mozilla Common Voice platform, users can donate their audio datasets by recording sentences as short voice clips, which Mozilla validates to ensure dataset quality upon submission.
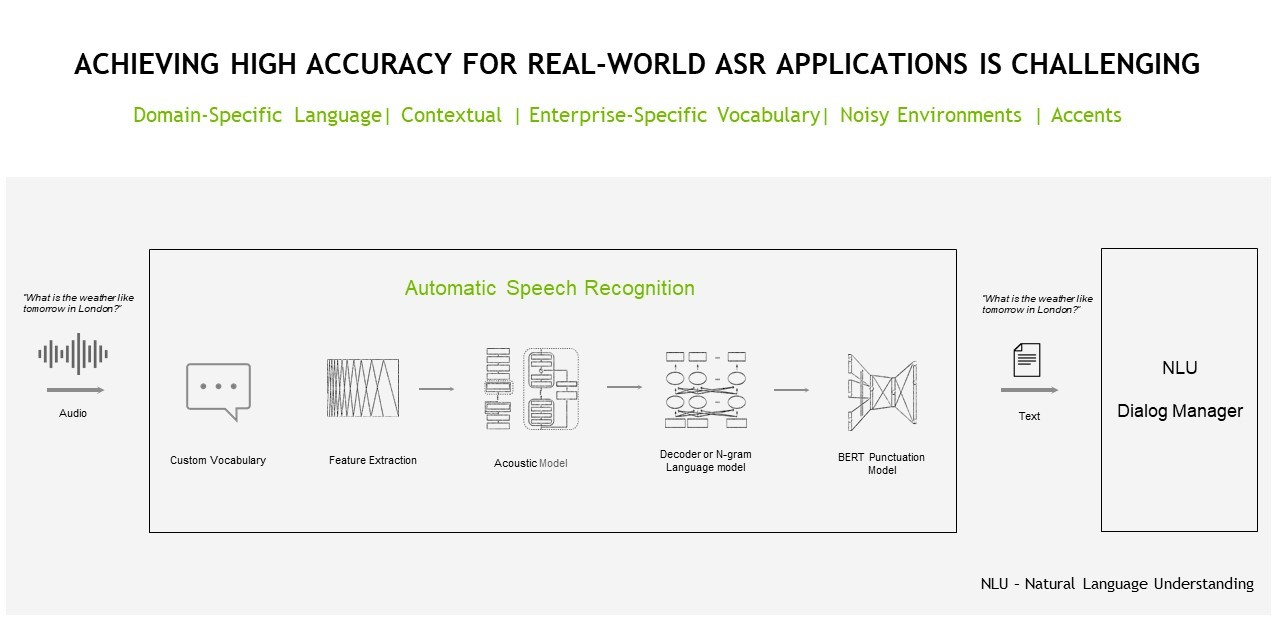
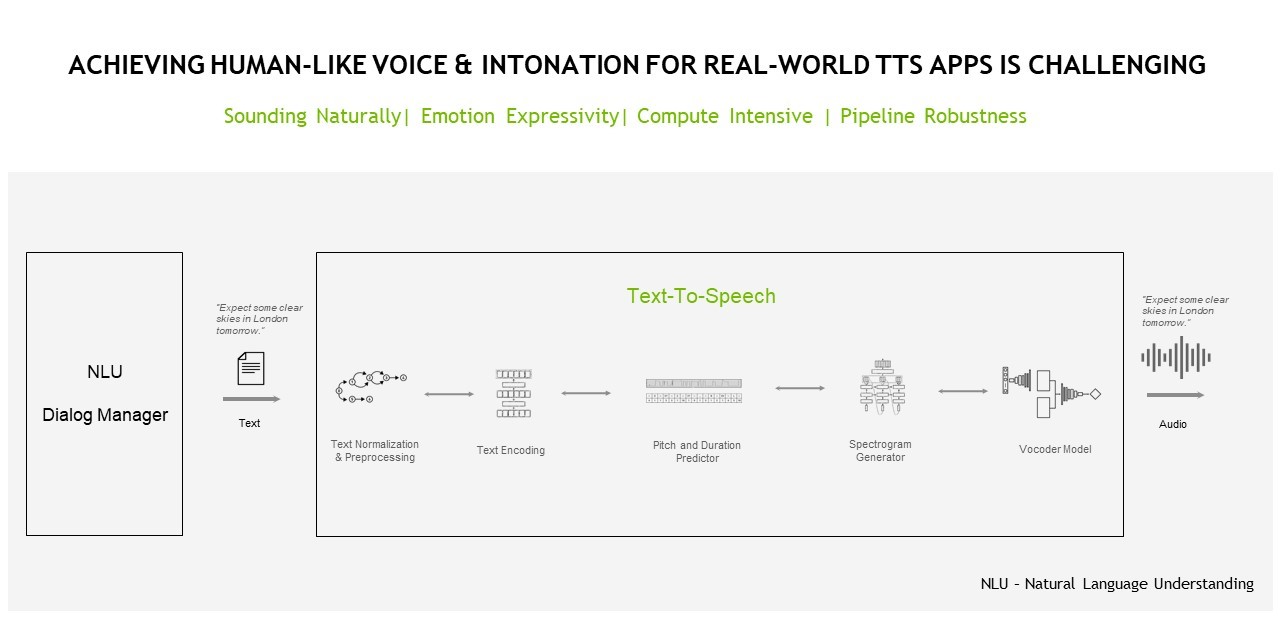
In the end, Nvidia wants to develop speech AI for several use cases, such as automatic speech recognition (ASR), artificial speech translation (AST) and text-to-speech.
And in the future, Nvidia is certain that the technology can also be used to solve real-time metaverse use cases.
"Today, we’re limited to only offering slow translation from one language to the other, and those translations have to go through text," he said. "But the future is where you can have people in the metaverse across so many different languages all being able to have instant translation with each other."
“The next step,” he added, “is developing systems that will enable fluid interactions with people across the globe through speech recognition for all languages and real-time text-to-speech.”