
Large language models (LLMs) are extremely capable, and as more began to experiment with the technology, more products are born.
The emergence of ChatGPT in late 2022 triggered a seismic shift in AI, igniting what became a global arms race in large language models. From that moment onward, every major tech company—and many startups—scrambled to develop their own powerful language models. The pace accelerated quickly as competitors sought to dethrone OpenAI.
And among them, include those from China.
Chinese firms poured resources into homegrown AI projects, including Tencent, Baidu, ByteDance, and startups like DeepSeek and Moonshot joined the race, each aiming to deliver compelling alternatives to ChatGPT.
DeepSeek notably made waves in early 2025 by releasing its DeepSeek-V3 model for a fraction of the cost of OpenAI’s models, gaining rapid user adoption and prompting Western AI giants to respond in kind
Amid this rising competition, Alibaba unveiled its own LLM series—Tongyi Qianwen, or Qwen. Since its debut in April 2023, Qwen has grown through successive generations like Qwen2.5 and Qwen3. These models have been deployed in both cloud services and open-source repositories both domestically and internationally, offering multilingual and multimodal capabilities.
And this time, its next breakthrough comes with the introduction of 'Qwen-Image.'
Meet Qwen-Image — a 20B MMDiT model for next-gen text-to-image generation. Especially strong at creating stunning graphic posters with native text. Now open-source.
Key Highlights:
SOTA text rendering — rivals GPT-4o in English, best-in-class for Chinese
In-pixel… pic.twitter.com/zT9CFLzWkV— Qwen (@Alibaba_Qwen) August 4, 2025
This new addition to Alibaba’s Qwen family, officially unveiled in August 2025, is a 20‑billion‑parameter multimodal foundation model built on MMDiT architecture.
It's especially designed to excel where many image generators fall short: embedding accurate, multilingual text directly into images.
It's no longer a secret that LLMs have made impressive strides in understanding and generating text, but when it comes to producing text within images, they often fall short. This is because rendering readable, accurate text in images is not a purely linguistic task—it’s a visual one. Instead of typing letters like a word processor, image-generating models have to "draw" each character pixel by pixel.
That makes things like font consistency, alignment, spacing, and legibility far more complex.
One major issue lies in the data these models are trained on.
Most image datasets scraped from the internet include logos, signs, memes, or distorted text that’s stylized or partially obscured.
This results in noisy training examples that confuse the model, making it difficult for it to learn how to create clean, standard typography. As a result, even when prompted with specific words, the model might generate garbled letters or produce something that looks like text from a distance but turns out to be nonsense up close.
Making things worse, LLMs don't have built-in logic for spelling and grammar, meaning that they cannot “check” their output.
They can’t run a spellchecker or validate grammar once the image is generated. They also cannot support different writing systems—like Chinese, Arabic, Latin, or Cyrillic—means the model has to juggle multiple layouts, character sets, and reading directions.
Editing existing text in an image adds another layer of complexity, since the model needs to seamlessly match fonts, lighting, perspective, and surrounding visuals.

To solve these problems, some models are being specifically optimized for image-based text generation.
Qwen-Image is trained on carefully curated datasets that emphasize typography, signage, and multilingual rendering.
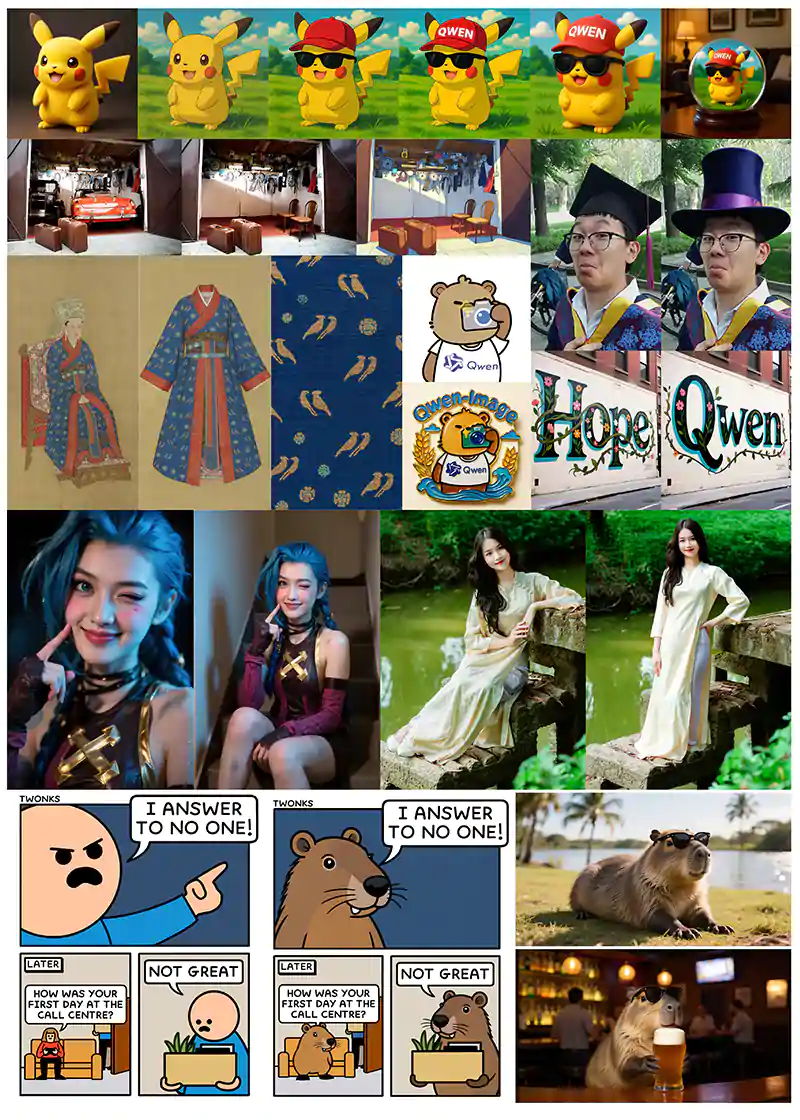
With architectures like MMDiT, it’s able to produce more consistent, readable text in both Chinese and English. It can handle paragraph-length prompts, mixed-language scenes, and even maintain visual coherence during editing tasks—all while staying open source and accessible.
Despite these advancements, generating flawless, editable text in images remains one of the most difficult challenges in multimodal AI.
It’s not just about knowing what to say—but mastering how to draw it.
— Qwen (@Alibaba_Qwen) August 4, 2025
Qwen‑Image demonstrates superior text rendering in both Chinese and English, supporting complex layouts, paragraph‑level semantics, and bilingual content within the same visual scene .
Benchmark results from GenEval, DPG, OneIG‑Bench, GEdit, and LongText‑Bench show that Qwen‑Image outperforms or matches the performance of models like GPT‑4.1, particularly in tasks that require delicate handling of typography or multilingual text integration. It also offers consistent and high‑quality editing features—style transfer, object addition or removal, detail enhancement, pose adjustments, and visual realism preservation during edits.
In early reactions from the AI community, some caution that the model may not yet match proprietary systems like Midjourney on overall image fidelity, especially in extremely detailed or stylized scenes.
Still, its open‑source nature, excellent prompt adherence, and multilingual text capabilities mark it as a disruptive and compelling alternative in the field.
This release underlines how Alibaba’s strategy has paid off.
Investors have responded positively to models like QwQ‑32B (part of the Qwen series), which rival other Chinese models like DeepSeek-R1 on reasoning benchmarks while offering greater computational efficiency.
The model’s open licensing policy allows it to run on consumer hardware, further amplifying its appeal in academic and developer circles.
— Qwen (@Alibaba_Qwen) August 4, 2025
As China’s tech sector eyes artificial general intelligence (AGI), models like Qwen and Qwen‑Image are central to the narrative—which now extends beyond China to the global AI ecosystem.
Alibaba’s resurgence in AI reflects a broader strategy to reclaim leadership after lagging behind OpenAI.
Alibaba’s strategy is clear: invest heavily in AI, pivot toward a research and open‑source ethos, and use powerful tools like the Qwen family to challenge global incumbents.
Qwen‑Image is not just another image model—it’s a statement of intent.
With vivid text rendering, responsive editing, and free access, it invites developers and creators to push the boundaries of visual content generation. In this rapid AI arms race, Qwen‑Image shows that open‑source innovation can match—and sometimes lead—where it matters most..
All of this makes Qwen a compelling contender in the LLM arena—not just inside China, but globally.
Its combination of open licensing, multimodal flexibility, enterprise integration, and competitive performance positions it as a worthy rival to ChatGPT. As the AI arms race continues unabated, models like Qwen show that competition is no longer confined to Silicon Valley.
More Demos pic.twitter.com/YTPgy5D2CW
— Qwen (@Alibaba_Qwen) August 4, 2025


























































































































































































































































































































































































